내용 보기
작성자
관리자 (IP : 172.17.0.1)
날짜
2021-01-14 08:46
제목
[C++] false sharing 이란?? (거짓공유)
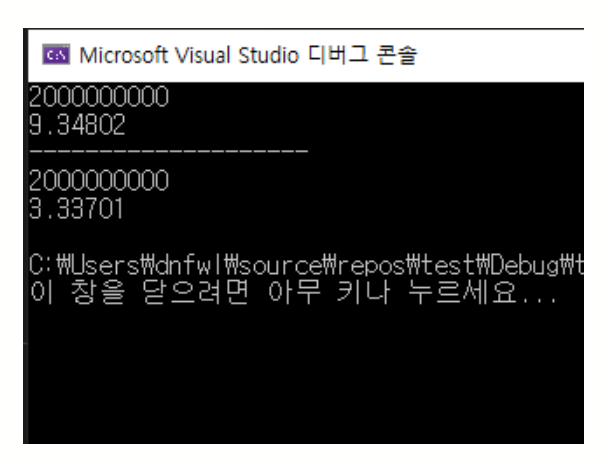
1. false sharing 이란??false sharing은 멀티 쓰레드 환경 + CPU의 멀티 코어에서 발생됩니다. cpu 내부의 코어와 코어간의 메모리 정보가 공유되어 하드웨어 적으로 병목현상이 일어나는 것을 뜻합니다. 설명하기에 앞서 false sharing이 일어난 코드를 보겠습니다. #include <iostream> #include <thread> #include <chrono> long long num1 = 0; long long num2 = 0; long long num3 = 0; void fun1() { for (long long i = 0; i < 1000000000; i++) num1 += 1; } void fun2() { for (long long i = 0; i < 1000000000; i++) num2 += 1; } void fun3() { for (long long i = 0; i < 2000000000; i++) { num3 += 1; } } int main() { auto beginTime = std::chrono::high_resolution_clock::now(); std::thread t1(fun1); //Multi Thread 실행 std::thread t2(fun2); //Multi Thread 실행 t1.join(); t2.join(); auto endTime = std::chrono::high_resolution_clock::now(); std::chrono::duration<double> resultTime = endTime - beginTime; printf("%lld\n", num1 + num2); std::cout << resultTime.count() << std::endl; printf("--------------------\n"); beginTime = std::chrono::high_resolution_clock::now(); fun3(); //Single Thread 실행 endTime = std::chrono::high_resolution_clock::now(); resultTime = endTime - beginTime; printf("%lld\n", num3); std::cout << resultTime.count() << std::endl; } 코드는 길어보이지만 간단한 코드 입니다. thread t1, t2는 fun1()과 fun2()를 실행하는 거고요. [결과] 9.34802초가 걸린 것이 Multi thread로 계산한 결과이고, 비슷하거나 빨라야 하는데 1초 차이도 아니고 6초 차이가 나버립니다. 이 현상을 알기 위해 CPU의 캐시구조를 알 필요가 있습니다. 2. CPU의 캐시 구조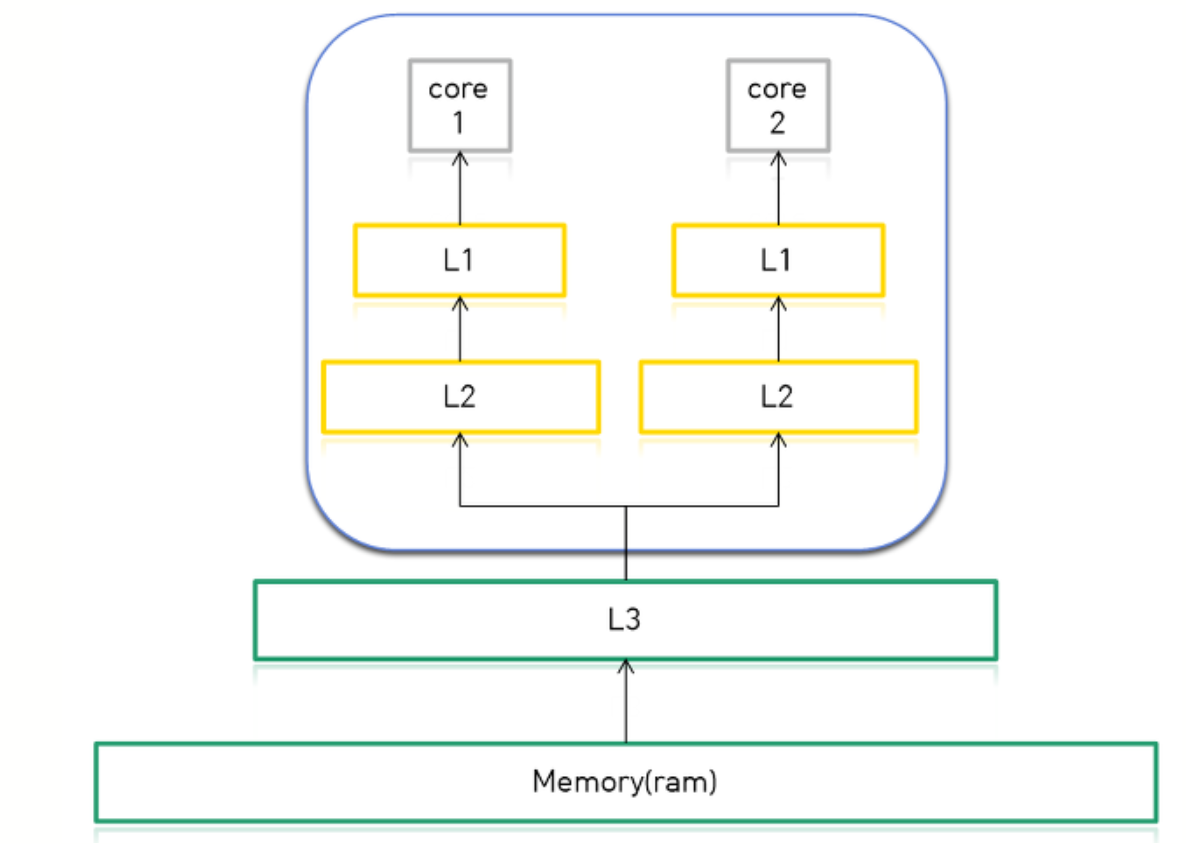 요즘 나오는 CPU들은 L1과 L2캐시가 코어에 있고 L3는 외부에 따로 나와있습니다.
코어로 전달되는 Cache Line, L1, L2, L3에 저장될 수 있는 용량은 사진과 같습니다. 왜?? 캐시는 자주 사용하는 데이터를 메모리까지(ram) 가지 않고 메모리보다 더 빠른 캐시에 저장함으로서
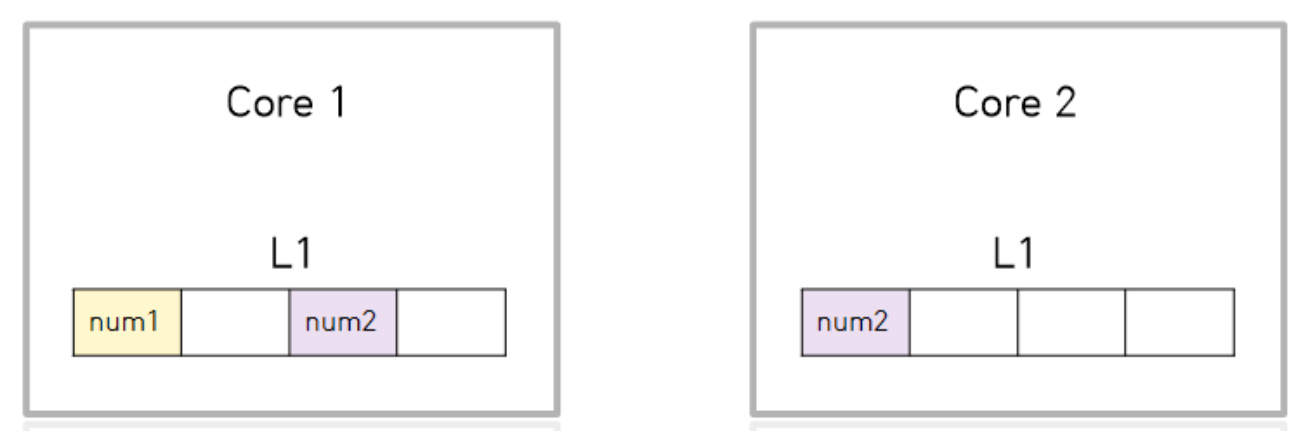
이런식으로 들어오게 됩니다. 해당 블록은 8바이트가 4개 있는 것이며 이해를 돕기위해 간단하게 표시했습니다.) 그래서 Core 2는 문제없이 연산하게 됩니다. 비록 Core 1에서 num2의 계산을 하지 않지만, 캐시 입장에선 데이터가 공유되어 무슨일이 일어날지 알 수 없습니다. 이는 데이터의 오류를 줄이고자 진행되는 매커니즘입니다. 그럼 Core 2는 계속 num2의 데이터 처리를 진행할까요?? 아닙니다. 이를 해결하는 방법은 패딩(padding)을 이용해 데이터를 64바이트로 채워주는 것입니다.
이런식으로 말이죠..... C++에서 제공하는 alignas()함수를 이용해 데이터에 패딩을 채워줄 수 있습니다. 아래는 패딩으로 채워준 코드입니다.#include <iostream> #include <thread> #include <chrono> alignas(64) long long num1 = 0; //바뀐 부분 alignas(64) long long num2 = 0; //바뀐 부분 long long num3 = 0; void fun1() { for (long long i = 0; i < 1000000000; i++) num1 += 1; } void fun2() { for (long long i = 0; i < 1000000000; i++) num2 += 1; } void fun3() { for (long long i = 0; i < 2000000000; i++) { num3 += 1; } } int main() { auto beginTime = std::chrono::high_resolution_clock::now(); std::thread t1(fun1); //Multi Thread 실행 std::thread t2(fun2); //Multi Thread 실행 t1.join(); t2.join(); auto endTime = std::chrono::high_resolution_clock::now(); std::chrono::duration<double> resultTime = endTime - beginTime; printf("%lld\n", num1 + num2); std::cout << resultTime.count() << std::endl; printf("--------------------\n"); beginTime = std::chrono::high_resolution_clock::now(); fun3(); //Single Thread 실행 endTime = std::chrono::high_resolution_clock::now(); resultTime = endTime - beginTime; printf("%lld\n", num3); std::cout << resultTime.count() << std::endl; }
제대로 동작 하니 1.67077초가 걸렸습니다. 자신의 CPU캐시의 크기를 얻어오는 메크로도 존재합니다. printf("%d\n", std::hardware_destructive_interference_size); //output : 64
class alignas(32) A { private: int num; char c; int arr[10]; }; struct alignas(64) B { private: int num; char c; int arr[10]; };
class __declspec(align(64)) A { //위치는 상관 없음 private: int num; char c; int arr[10]; }; __declspec(align(64)) struct B { //위치는 상관 없음 private: int num; char c; int arr[10]; };
|



출처1
https://hwan-shell.tistory.com/230
출처2