내용 보기
작성자
관리자 (IP : 172.17.0.1)
날짜
2021-07-22 14:50
제목
[SQL] 클러스터 인덱스 / 넌 클러스터 인덱스
|
오늘은 인덱스의 종류인 클러스터 인덱스, 넌 클러스터 인덱스에 대해 정리해보겠습니다. 일단 인덱스란 데이터를 빠르게 검색할 수 있게 해주는 객체입니다. 컬럼을 정렬한 후에 데이터를 빠르게 찾을 수 있도록 도와주는 역할을 합니다. 책으로 비유하자면 색인을 의미합니다.
인덱스를 생성하면 무조건 데이터를 빠르게 검색할 수 있을까요? 대답은 노! 그건 아닙니다. 인덱스를 무작정 생성한다고 좋은 방법은 아닙니다. 인덱스를 생성하면 인덱스를 위한 디스크 공간이 필요하고, 인덱스를 가진 테이블에 DML 작업을 할 경우 더 많은 비용과 시간이 필요합니다. 때문에 인덱스를 생성 시 해당 테이블의 요도를 정확하게 파악한 후에 상황에 맞게 적절한 칼럼으로 Clustered Index와 Non Clustered Index를 구성해야 합니다.
인덱스의 종류
클러스터 인덱스
넌 클러스터 인덱스
쉽게 책에 비유하자면 클러스터 인덱스는 페이지를 알기 때문에 바로 그 페이지를 펴는 것이고, 넌 클러스터 인덱스는 뒤에 목차에서 찾고자 하는 내용의 페이지를 찾고 그 페이지로 이동하는 것과 같습니다. 테이블 스캔은 처음부터 한 장씩 넘기면서 내용을 찾는 것과 같습니다.
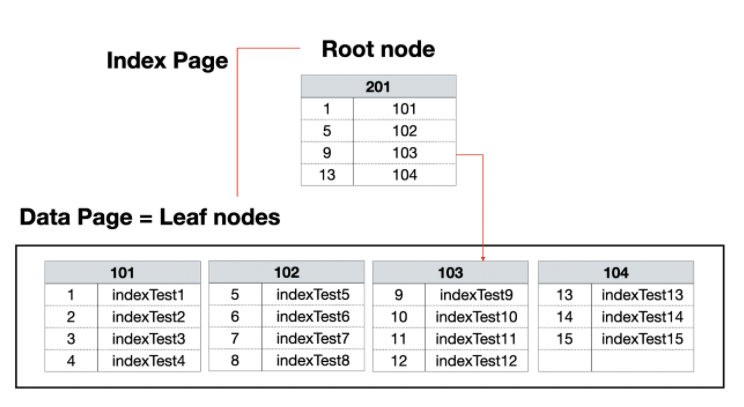
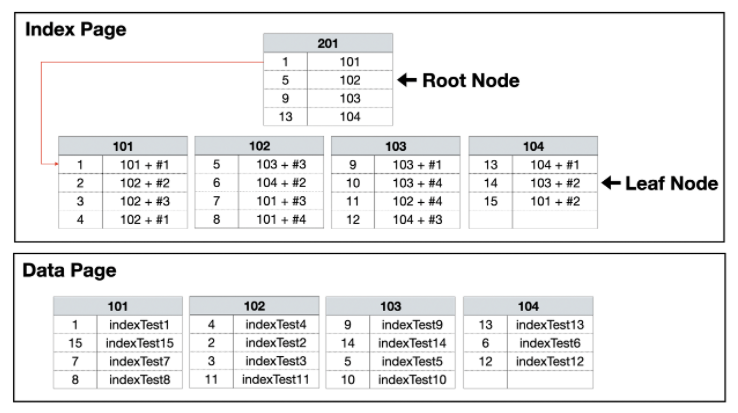
다음은 클러스터 인덱스와 넌크러스터 인덱스의 구성 방식을 그림으로 살펴보겠습니다.
클러스터 인덱스클러스트형 인덱스를 구성하려면 행 데이터를 해당 열로 정렬한 후에 루트 페이지를 만들게 됩니다. 즉 데이터 페이지는 리프 노드와 같은 것을 확인할 수 있습니다.
넌 클러스터 인덱스넌 클러스트형 인덱스는 데이터 페이지를 건들지 않고 , 별도의 장소에 인덱스 페이지를 생성합니다. 우선 인덱스 페이지의 리프 페이지에 인덱스로 구성한 열을 정렬하고 데이터 위치 포인터를 생성합니다. 데이터의 위치 포인트는 클러스터형 인덱스와 달리 '페이지 번호 + #오프셋'이 기록되어 바로 데이터 위치를 가리킵니다. indexTest2로 예를 들면 102번 페이지의 두 번째(#2)에 데이터가 있다고 기록하게 됩니다. 그러므로 이 데이터 위치 포인터는 데이터가 위치한 고유한 값이 됩니다.
결론클러스터 인덱스는 데이터 위치를 바로 알기 때문에 그 데이터로 바로 접근할 수 있고, 넌 클러스터 인덱스는 인덱스 페이지를 한번 거쳐서 데이터에 접근하는 방식이다.
- 참고 - RID란? 데이터 위치 포인터를 RID(Row ID) 라 부릅니다. 실제로는 해당하는 행의 '파일 그룹 번호-데이터 페이지 번호-행의 순번(데이터 페이지 오프셋)'으로 구성되는 포인팅 정보입니다. |
출처1
https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
출처2