내용 보기
작성자
관리자 (IP : 172.17.0.1)
날짜
2020-08-28 01:58
제목
[C#] CLR via C# (4th Edition) - PART 1
|
Jeffrey Richter Microsoft Press 2012
PART 1 CLR 기본
Chapter 1 CLR 실행 모델 Microsoft .NET Framework은 많은 개념과 기술 그리고 용어들을 소개하고 있다. 이번 장의 목표는 여러분에게 .NET Framework가 어떻게 설계되었는지에 대해 설명하고, 프레임워크가 포함하고 있는 몇몇 기술들을 소개하고, 여러분이 앞으로 보게 될 많은 용어들을 정의하는 것이다. 소스 코드를 관리 모듈로 컴파일하기 Common Language Runtime(CLR)은 다양하고 서로 다른 프로그래밍 언어에 의해 사용 가능한 런타임이다. CLR의 핵심 기능들(메모리 관리, 어셈블리 로딩, 보안, 예외 처리, 그리고 스레드 동기화)은 이를 목적으로 하는 모든 언어들에서 사용 가능하다. 관리 모듈은 CLR 실행을 요구하는 표준 32비트 윈도우즈 포터블 실행(PE32) 파일이거나 아니면 64비트 윈도우 포터블 실행(PE32+) 파일이다. 그런데, 관리 어셈블리는 항상 윈도우에서의 Data Execution Prevention (DEP)와 Address Space Layout Randomization (ASLR)의 이점을 가진다. 이 두개의 특징은 여러분의 전체 시스템의 보안을 향상시킨다. IL을 만드는 것 뿐만 아니라, CLR을 목적으로 하는 모든 컴파일러는 전체 메타데이터를 만들어서 관리 모듈에 집어 넣는다. 요약하면, 메타데이터는 모듈 안에서 정의된 타입과 그들의 멤버와 같은 것들을 서술하는 데이터 테이블 집합이다. 또한 메타데이터는 외부에서 참조되는 타입과 그들의 멤버들과 같은 관리 모듈이 참조하는 것들을 가리키는 테이블을 갖는다. 타입 라이브러리와 IDL과는 달리, 메타데이터는 항상 IL 코드를 포함하고 있는 파일과 묶인다. 사실 메타데이터는 코드와 같은 EXE/DLL 안에 항상 내장되어, 이 두개가 분리될 수 없다. 컴파일러는 메타데이터와 코드를 동시에 생산하고 이 둘을 같은 관리 모듈에 묶기 때문에, 메타데이터와 그것이 서술하는 IL 코드는 결코 어긋날 수 없다.
관리 모듈들을 어셈블리로 묶기 CLR은 사실 모듈들과 동작하지 않고, 어셈블리와 동작한다. 어셈블리는 처음엔 파악하기 어려운 추상적 개념이다. 첫번째로 어셈블리는 하나 이상의 모듈 혹은 리소스 파일들의 논리적 그룹이다. 두번째로 어셈블리는 재사용, 보안 그리고 버전관리의 가장 작은 단위이다. 여러분이 선택하는 컴파일러 혹은 툴에 따라, 단일 파일 혹은 다중 파일 어셈블리를 만들어 낼 수 있다. CLR 세계에서, 어셈블리는 우리가 컴포넌트라 부르는 그것이다. 매니페스트(manifest)는 간단한 또다른 메타데이터 테이블 집합이다. 이들 테이블은 어셈블리를 구성하는 파일들과 어셈블리 내의 파일에 의해 구현된 공용으로 익스포트된 타입들과 그리고 어셈블리에 연결된 리소스 혹은 데이터 파일들을 서술한다.
Common Language Runtime을 로딩하기 실행 파일이 동작할 대, 윈도우는 해당 애플리케이션이 32비트 혹은 64비트의 주소 공간을 필요로 하는지를 결정하기 위해 EXE 파일의 헤더를 검사한다. PE32 헤더를 가지는 파일은 32비트 혹은 64비트 주소 공간에서 동작할 수 있고, PE32+ 헤더를 가지는 파일은 64비트 주소 공간을 요구한다. 윈도우는 또한 헤더 안에 내장된 CPU 아키텍처 정보를 검사하여 그것이 컴퓨터의 CPU 타입과 일치하는 지를 확인한다. 마지막으로, 64비트 버전의 윈도우는 32비트 윈도우 애플리케이션이 동작하게 하는 기술을 제공한다. 이 기술은 Wow64(for Wondows on Windows 64)라 불린다. 윈도우가 32비트 혹은 64비트 프로세스를 생성할지를 결정하기 위해 EXE 파일 헤더를 검사한 후, 윈도우는 MSCorEE.dll의 x86, x64 혹은 ARM 버전을 그 프로세스의 주소 공간에 로딩한다. 그런 후에 그 프로세스의 주 스레드는 MSCorEE.dll 안에 정의된 메소드를 호출한다. 이 메소드는 CLR을 초기화하고 EXE 어셈블리를 로딩한 후, Main 함수를 호출한다. 이 시점에, 관리 애플리케이션이 실행된다. 여러분의 어셈블리 코드를 실행하기 IL은 Microsoft에 의해 만들어진 CPU 독립적인 기계 언어이다. IL은 대부분의 CPU 기계 언어보다 훨씬 고수준의 언어이다. IL은 객체 타입을 접근하고 조작할 수 있으며 객체를 생성하고 초기화하는 지시어를 가지며, 객체에 대한 가상 함수를 호출할 수 있고, 배열 요소를 직접 조작할 수 있다. 이것은 또한 에러 처리를 위해 예외를 던지고 잡는 명령어도 가진다. 여러분은 IL을 객체 지향적 기계어로 생각할 수 있다. 메소드를 수행하려면, 그 메소드의 IL은 먼저 네이티브 CPU 명령어로 전환되어야 한다. 이것은 CLR의 JIT(Just-in-time) 컴파일러의 작업이다. 어떤 메소드가 처음 호출될 때만 성능상의 영향이 발생한다. 그 메소드에 대한 이어지는 모든 호출들은 네이티브 코드 수행과 같은 속도로 실행되는데, 네이티브 코드에 대한 검증과 컴파일이 다시 수행될 필요가 없기 때문이다. 코드 최적화에 영향을 미치는 2개의 C# 컴파일러 스위치가 있다: /optimize와 /debug.
/optimize- 옵션으로, C# 컴파일러에 의해 만들어진 최적화 안된 IL 코드는 많은 NOP 명령어들과 코드의 다음 줄로 넘어가는 브랜치들을 포함한다. 최적화된 IL 코드를 만들 때, C# 컴파일러는 이러한 NOP와 브랜치 명령들을 제거하는데, 이는 디버거에서 single-step through를 어렵게 만든다. 게다가, 컴파일러는 /debug(+/full/pdbonly) 스위치에서만 PDB 파일을 생성한다. /debug:full 스위치는 JIT 컴파일러에게 여러분이 어셈블리를 디버깅할 것이라고 말하는 것인데, JIT 컴파일러는 네이티브 코드가 어떤 IL 명령어로부터 왔는지를 추적한다. 여러분은 아마도 믿기 어렵겠지만, 나를 포함한 많은 사람들은 관리 애플리케이션이 실제로는 비관리 애플리케이션을 능가할 수 있다고 믿는다. 이렇게 생각하는 데에는 많은 이유가 있다. 예를 들어, JIT 컴파일러가 IL 코드를 런타임시에 네이티브 코드로 컴파일할 때, 컴파일러는 실행 환경에 대해 비관리 컴파일러보다 더 많이 알고 있다. IL과 검증 내 생각에, IL의 가장 큰 이점은 IL이 바탕이 되는 CPU로부터 추상화될 수 있다는 점이 아니다. IL의 가장 큰 이점은 애플리케이션의 견고함과 보안을 제공하는 것에 있다. IL을 네이티브 CPU 명령어로 컴파일하는 동안, CLR은 검증이라 불리는 과정을 구행한다. 검증은 고수준의 IL 코드를 조사하여 모든 코드가 안전함을 확인한다. 관리 코드를 검증함으로써, 그 코드가 부적절하게 메모리를 접근하지 않고, 다른 애플리케이션의 코드를 악의적으로 침범하지 않음을 알 수 있다. 이는 여러분은 단일 윈도우 가상 주소 공간에서 여러개의 관리 애플리케이션을 동작시킬 수 있음을 의미한다.
안전하지 않은 코드
네이티브 코드 발생기 툴: NGen.exe .NET Framework와 함께 배포되는 NGen.exe 툴은 애플리케이션을 사용자 장비에 설치할 때 IL 코드를 네이티브 코드로 컴파일하는데 사용될 수 있다. 코드가 설치시에 컴파일되기 때문에, CLR의 JIT 컴파일러는 런타임시에 IL 코드를 컴파일할 필요가 없으므로, 애플리케이션의 성능을 향상시킬 수 있다. The Framework Class Library .NET Framework는 FCL을 포함한다. FCL는 수천개의 타입을 정의하는 DLL 어셈블리 집합으로서, 각각의 타입은 기능들을 제공한다. The Common Type System 타입은 CLR의 근간이기 때문에, Microsoft는 공식 명세인 CTS를 작성하여 타입들이 어떻게 정의되고 동작하는지를 서술하였다. CTS 명세는 타입은 다음과 같은 멤버를 0개 이상 포함할 수 있음을 명시한다.
CTS는 또한 타입의 가시성과 타입의 멤버의 접근성에 대한 규칙을 명시한다.
또다른 CTS 규칙은 모든 타입들은 사전에 정의된 타입인 System.Object로부터 상속되어야 한다는 것이다. 이 Object 타입은 모든 다른 타입들의 근간이므로 모든 타입의 인스턴스는 최소한의 행동 집합을 가짐을 보장한다.
The Common Language Specification Interoperability with Unmanaged Code Chapter 2 애플리케이션과 타입을 빌드, 패키징, 배포, 관리하기
이번 장에서, 나는 여러분 애플리케이션 만을 위한 어셈블리를 빌드하는 기본 방법에 초점을 맞출 것이다.
.NET Framework 배포 목표 타입을 모듈로 빌드하기 Response Files Response file은 컴파일러 명령줄 스위치 집합을 포함하고 있는 텍스트 파일이다. 여러분은 CSC.exe를 실행시킬 때, 컴파일러는 response file을 열어서 그 안에 명시된 모든 스위치들을 사용한다. A Brief Look at Metadata Combining Modules to Form an Assembly Adding Assemblies to a Project by Using the Visual Studio IDE Using the Assembly Linker Adding Resource Files to an Assembly Assembly Version Resource Information Version Numbers Culture Simple Application Deployment (Privately Deployed Assemblies) Simple Administrative Control (Configuration) Chapter 3 Shared Assemblies and Strongly named Assemblies
In this chapter, I'll concentrate on creating assemblies that can be accessed by multiple applications. The assemblies that ship with the Microsoft .NET Framework are an excellent example of globally deployed assemblies, because all managed applications use types defined by Microsoft in the .NET Framework Class Library (FCL).
Two Kinds of Assemblies, Two Kinds of Deployment Giving an Assembly a Strong Name The Global Assembly Cache Building an Assembly That References a Strongly named Assembly Strongly named Assemblies Are Tamper-Resistant Delayed Signing Privately Deploying Strongly Named Assemblies How the Runtime Resolves Type References Advanced Administrative Control (Configuration) Publisher Policy Control
PART 2 타입 설계
Chapter 4 타입 기본 이번 장에서는, 타입과 CLR과 함께 동작하기 위한 기본 개념을 소개할 것이다. 또한 모든 타입이 가져야 하는 동작(behavior)의 최소 집합을 얘기할 것이다. 또한 타입 안정성, 네임스페이스, 어셈블리 그리고 여러분이 하나의 타입을 다른 타입으로 캐스팅할 수 있는 다양한 방법에 대해서도 얘기한다. 마지막으로 타입, 객체, 스레드 스택, 관리힙들 모두가 런타임에 서로 어떻게 연관되어 있는지를 소개하는 것으로 이번 장을 마무리한다.
모든 타입은 System.Object로부터 파생된다 모든 타입은 결국엔 System.Object로부터 파생되기 때문에, 모든 타입의 모든 객체는 최소한의 메소드 집합을 가짐을 보장한다.
System.Object의 공용 메소드
CLR은 모든 객체가 new 연산자를 사용하여 생성되어야 함을 요구한다. new 연산자는 다음과 같은 일을 수행한다.
타입들 간의 캐스팅 C# is와 as 연산자로 캐스팅하기 is 연산자는 객체가 주어진 타입으로 변환 가능한지를 확인하며, 표현식의 결과는 불린이다. is 연산자는 결코 예외가 발생하지 않는다.
위 코드에서, CLR은 실제로 객체 타입을 2번 확인한다. 이런 프로그래밍 패러다임은 꽤 자주 사용되기 때문에, C#은 이 코드를 간소화하고 성능향상을 위해 as 연산자를 제공한다.
C#은 타입이 변환 연산자 메소드를 정의하는 것을 허용한다. 이들 메소드는 오직 캐스트 표현식을 사용할 때만 호출된다. 이들은 C# as 혹은 is 연산자를 사용할때는 결코 호출되지 않는다. 네임스페이스와 어셈블리 네임스페이스는 연관된 타입들의 논리적 묶음을 고려한 것으로서, 개발자는 보통 특정 타입을 위치시키는데 편하게 하고자 네임스페이스를 사용한다. 런타임시에 이것들이 어떻게 연관되어 있는가 Chapter 5 기본타입, 참조타입 그리고 값타입 이번 장에서는, Microsoft .NET Framework 개발자로서 여러분들이 마주하게 될 타입들의 서로 다른 종류들을 논의할 것이다.
프로그래밍 언어의 기본타입 (Primitive Types) 컴파일러가 직접 지원하는 모든 데이터 타입들을 기본 타입(primitive type)이라 부른다. 기본 타입은 FCL에 존재하는 타입들과 직접 연결된다.
Checked and Unchecked 기본타입 연산 CLR은 기본타입 연산의 오버플로에 대해 컴파일러가 원하는 방식을 선택할 수 있도록 하는 명령어를 제공한다. add 명령어는 오버플로를 확인하지 않는다. 하지만 add.ovf 명령어는 두 값을 더할때 오버플로가 발생하면 System.OverflowException 예외를 던진다. C# 컴파일러가 오버플로를 제어하는 방법은 /checked+ 컴파일러 스위치를 사용하는 것이다. 이 스위치는 컴파일러에게 add, subtract, multiply, conversion IL 명령의 오버플로 확인 버전을 사용하라고 말해준다. 이 코드는 약간 느려지는데 CLR이 이들 연산에 대해 오버플로가 발생하는지는 검사해야 하기 때문이다. C#은 또한 checked와 unchecked 연산자를 제공하여 프로그래머가 특정 코드에서만 오버플로를 제어할 수 있도록 해준다. System.Decimal 타입은 매우 특별한 타입이다. 비록 많은 프로그래밍 언어들(C#과 Visual Basic을 포함하여)이 Decimal을 기본타입으로 간주하지만, CLR은 그렇지 않다. 이는 CLR이 Decimal 값을 조작하는 IL 명령어를 가지고 있지 않다는 뜻이다. 여러분이 Decimal 값을 사용하는 코드를 컴파일할 때, 컴파일러는 실제 연산을 수행하기 위해 Decimal의 멤버들을 호출하는 코드를 만들어낸다. 이는 Decimal 값을 조작하는 것이 CLR 기본값을 조작하는 것보다 더 느리다는 것을 의미한다. 또한 Decimal 값을 조작하는 IL 명령어가 없기 때문에, checked와 unchecked 연산자, 문장 그리고 컴파일러 스위치는 아무런 효과도 없다. 이와 비슷하게 System.Numeric.BigInteger 타입 또한 임의의 큰 숫자를 표현하기 위해 내부적으로 UInt32 배열을 사용하기 때문에 특별하다. 참조타입과 값타입 CLR은 2종류의 타입을 지원한다: 참조타입과 값타입. 참조타입은 항상 관리힙으로부터 할당되고, C#의 new 연산자는 그 객체의 메모리 주소를 반환한다. 여러분은 참조타입을 사용할 때 다음과 같은 성능상의 고려를 해야 한다.
간단하고 자주 사용되는 타입들의 성능을 개선하기 위해, CLR은 값타입이라 불리는 경량 타입들을 제공한다. 값타입 인스턴스는 보통 스레드 스택에 할당된다(비록 이들이 참조타입 객체 안의 필드로 내장될 수도 있지만). 그 인스턴스를 나타내는 변수는 인스턴스에 대한 포인터를 포함하지 않는다. 그 변수는 인스턴스 자체의 필드를 포함한다. .NET Framework SDK 문서는 어떤 타입이 참조타입이고 어떤 것이 값타입인지를 명확하게 구분한다. 클래스라 불리는 타입은 참조타입이다. 반면에, 구조체 혹은 열거형은 값타입이다. 모든 구조체는 System.ValueType 추상 타입으로 바로 파생된다. System.ValueType은 System.Object 타입에서 바로 파생된다. 모든 값타입은 System.ValueType으로부터 파생되어야 한다. 모든 열거형은 System.Enum 추상 타입에서 파생되어야 하는데, 이 타입은 System.ValueType에서 파생된다. CLR과 모든 프로그래밍 언어는 열거형을 특별하게 취급한다. 여러분 자신의 값타입을 정의할 때 여러분은 기본 타입을 선택할 수는 없지만, 값타입은 여러분이 선택하는 하나 이상의 인터페이스를 구현할 수는 있다. 또한 모든 값타입은 봉인되어 있어서, 값타입이 다른 참조타입 혹은 값타입의 기본 타입으로서 사용되는 것을 방지한다.
위 줄이 쓰여진 방식은 마치 SomeVal 인스턴스가 관리힙에 할당될 것처럼 보이지만, C# 컴파일러는 SomeVal이 값타입임을 알기 때문에 SomeVal 인스턴스를 스레드 스택에 할당하는 코드를 생성한다. C#은 또한 값타입 인스턴스의 모든 필드들이 0이 되도록 한다.
여러분 자신만의 타입을 설계할 때, 참조타입 대신에 값타입으로 정의할 지를 주의깊에 고려해야 한다. 어떤 경우엔, 값타입이 더 좋은 성능을 줄 수 있다. 특히, 다음 문장들이 참일 경우 값타입으로 선언해야 한다.
여러분 타입의 인스턴스의 크기도 또한 고려 조건중의 하나인데, 기본적으로 인자는 값으로 넘겨지기 때문이다. 그래서 이전 조건에 더하여, 여러분은 다음 문장중의 하나라도 참인지를 고려해야 한다.
성능을 개선하기 위해, CLR은 타입의 필드를 재배열할 수 있다. 예를 들어, CLR은 메모리상의 필드들을 재배열하여 객체 참조가 함께 묶이거나 데이터 필드가 올바르게 맞춰지고 압축되도록 할 수 있다. 하지만, 여러분이 타입을 정의할 때, 여러분은 CLR에게 타입의 필드가 정의된 순서대로 유지될 지 아니면 CLR이 재배열하게 할 지를 결정할 수 있다. 여러분은 여러분이 정의하는 클래스 혹은 구조체 상에 System.Runtime.InteropServices.StructLayoutAttribute 어트리뷰트를 적용하여 CLR에게 무엇을 할지를 말해줄 수 있다. CLR이 필드를 배열시키게 하려면 LayoutKind.Auto를, CLR이 여러분의 필드 배치를 보존하게 하려면 LayoutKind.Sequential을, 아니면 오프셋을 사용하여 메모리 내에서 필드를 명시적으로 위치시키려면 LayoutKind.Explicit를 어트리뷰트의 생성자에 넘겨줄 수 있다. Microsoft C# 컴파일러는 참조타입(클래스)에는 LayoutKind.Auto를, 값타입(구조체)에는 LayoutKind.Sequential을 선택한다. 구조체는 보통 비관리 코드와 함께 상호동작 하는 경우가 있기 때문에, 구조체의 필드들은 프로그래머가 정의한 순서대로 있어야 한다는 것이 C# 컴파일러 팀의 생각이다. 하지만 여러분이 비관리 코드와 함께 동작하지 않는 값타입을 만든다면, 다음과 같이 C# 컴파일러의 기본 동작을 변경할 수 있다.
값타입을 박싱하고 언박싱하기 박싱(boxing)이라 불리는 메커니즘을 사용하여 값타입을 참조타입으로 변환하는 것이 가능하다. 내부적으로 값타입의 인스턴스가 박싱되는 과정은 다음과 같다.
위 코드는 ArrayList의 요소 0에 포함되어 있는 참조(혹은 포인터)를 취하여 Point 값타입 인스턴스인 p에 넣는 것이다. 이것이 동작하기 위해서는, 박싱된 Point 객체안에 포함된 모든 필드들이 값타입 변수인 스레드 스택상의 p에 복사되어야 한다. CLR은 이 복사를 2단계로 수행한다. 먼저 박싱된 Point 객체안의 Point 필드들의 주소를 얻는다. 이 과정을 언박싱(unboxing)이라 부른다. 그런 다음, 이들 필드의 값을 힙으로부터 스택 기반의 값타입 인스턴스로 복사한다. 언박싱은 박싱의 정확한 반대 과정이 아니다. 언박싱은 박싱에 비해 매우 비용이 작다. 언박싱은 단지 객체 내에 포함되어 있는 날것의 값타입에 대한 포인터를 획득하는 과정이다. 결국 그 포인터는 박싱된 인스턴스 안의 언박싱된 부분을 가리킨다. 그래서, 박싱과 달리, 언박싱은 메모리의 바이트 복사를 포함하지 않는다. 즉, 언박싱 연산 다음에는 보통 필드 복사가 수반된다. 언빅싱 값타입이 동기화 블록 인덱스를 가지지 않기 때문에, 여러분은 System.Threading.Monitor 타입의 메소드를 사용하여(혹은 C#의 lock 문장을 사용하여) 여러 스레드에서 그 인스턴스에 대한 접근을 동기화할 수 없다. 비록 언박싱된 값타입이 타입 객체 포인터를 가지지는 않지만, 여러분은 여전히 그 타입에 의해 상속되거나 재정의된 가상 메소드들(Equals, GetHashCode 혹은 ToString과 같은)을 호출할 수 있다. 만약 여러분의 값타입이 이 가상 메소드들 중의 하나를 재정의한다면, CLR은 그 메소드를 비가상적으로 호출하는데 값타입은 암묵적으로 봉인되어 있고 이들로부터 어떠한 타입도 파생될 수 없기 때문이다. 추가로 가상 함수를 호출하는데 사용되는 값타입 인스턴스는 박싱되지 않는다. 하지만 만약 여러분의 가상 메소드 재정의가 그 메소드의 기본 타입의 구현부를 호출한다면, 기본타입의 구현부가 호출될 때 값타입 인스턴스는 박싱되어 힙 객체에 대한 참조가 this 포인터로 건네지고 기본 메소드로 넘겨진다. 그러나, 비가상 상속 메소드(GetType 혹은 MemberwiseClone과 같은) 호출은 항상 값타입을 박싱되도록 하는데 이들 메소드들이 System.Object에 정의되어 있어서 그 메소드들이 this 인자가 힙상의 객체를 가리킬 것으로 예상하고 있기 때문이다. 추가로, 값타입의 언박싱된 인스턴스를 그 타입의 인터페이스 중 하나로 캐스팅하는 것은 그 인스턴스를 박싱되도록 요구하는데, 이는 인터페이스 변수는 항상 힙상의 객체에 대한 참조를 포함해야 하기 때문이다.
인터페이스를 사용하여 박싱된 값타입의 필드를 수정하기 (그리고 여러분이 이것을 하지 말하야 하는 이유)
객체 동등성(Equality) 과 동일성(Identity)
Object의 Equals()의 기본 구현은 동일성을 구현한 것이지, 값의 동등성을 구현한 것이 아니다. 불운하게도, Object의 Equals() 메소드는 합당하지 않고, 이런 식으로 구현되어서는 안된다. 다음은 Equals 메소드를 내부적으로 올바르게 구현하는 방법이다.
그러므로, Microsoft는 Object의 Equals 메소드를 다음과 같은 구현해야 한다.
만약 여러분이 동일성을 확인하려 한다면(만약 2개의 참조가 같은 객체를 가리키는지를 확인하려 한다면), 여러분은 ReferenceEquals()를 호출해야 한다. 여러분은 C# == 연산자를 사용해서는 안되는데, 피연산자 타입중의 하나가 ==연산자를 중복정의할 수도 있기 때문인데, 그러면 그것의 의미는 동일성이 아닐 수 있기 때문이다. 하지만, System.ValueType은 Object의 Equals() 메소드를 재정의하여 값의 동등성 확인(동일성 확인이 아닌)을 올바르게 구현한다.
내부적으로, ValueType의 Equals 메소드는 위의 3단계를 수행하기 위해 리플렉션을 사용한다. CLR의 리플렉션 메커니즘은 느리기 때문에, 여러분은 여러분 자신의 Equals() 메소드를 재정의해야 한다. 물론 여러분의 구현에서 base.Equals를 호출하지 말라. Equals 메소드를 재정의할 때, 여러분이 하기 원할지도 모르는 몇가지가 더 있다.
객체 해시 코드(Hash Codes) 만약 여러분이 타입을 정의하고 Equals 메소드를 재정의하면, 여러분은 또한 GetHashCode 메소드를 재정의해야 한다. 사실 Microsoft의 C# 컴파일러는 만약 여러분은 GetHashCode 메소드 재정의 없이 Equals 메소드를 재정의하면 경고를 내보낸다. Equal을 정의하는 타입이 또한 GetHashCode도 정의해야 하는 이유는 System.Collections.Hashtable 타입, System.Collections.Generic.Dictionary 타입, 그리고 몇몇 다른 콜렉션 타입들이 동일한(equal) 두개의 타입이 같은 해시코드 값을 가져야 함을 요구하기 때문이다. 그래서 만약 여러분이 Equal을 재정의하면, 여러분은 또한 GetHashCode를 재정의하여 동등성을 계산하는데 사용되는 알고리즘이 그 객체의 해시코드를 계산하는데 사용하는 알고리즘과 부합함을 보장해야 한다. GetHashCode 메소드를 정의하는 것은 쉽고 직관적일 수 있다. 하지만 여러분의 데이터 타입과 데이터 분산에 따라, 값이 잘 분산되는 범위를 반환하는 해시 알고리즘을 얻는 것이 까다로울 수 있다. Point 객체에 적당한 예제는 다음과 같다.
dynamic 기본타입 개발자가 리플렉션을 사용하거나 다른 컴포넌트와 통신하는 것을 쉽게 해주기 위해, C# 컴파일러는 표현식의 타입을 dynamic으로 표시해 주는 방법을 제공한다. 여러분은 또한 표현식의 결과를 변수에 넣을 수 있고 그 변수의 타입을 dynamic으로 표시할 수도 있다. 이런 dynamic 표현식/변수는 그 후에 필드, 속성/인덱서, 메소드, 델리게이트, 그리고 단항/이항/변환 연산자와 같은 멤버를 호출하는데 사용될 수 있는데, 컴파일러는 원하는 연산을 설명하기 위해 특별한 IL 코드를 생성한다. 이 특별한 코드는 payload로 언급된다. 런타임시에, 해당 payload 코드는 동적 표현식/변수에 의해 현재 참조되는 객체의 실체 타입에 근거하여 수행될 정확한 연산을 결정한다. 필드, 메소드 파라미터, 혹은 메소드 반환타입의 타입이 dynamic으로 명시되면, 컴파일러는 이 타입을 System.Object 타입으로 변환하고, 메타데이터에 그 필드, 파라미터 혹은 반환 타입에 System.Runtime.CompilerServices.DynamicAttribute 인스턴스를 적용시킨다. 만약 지역 변수가 dynamic으로 명시되면, 그 변수의 타입은 object 타입으로 되지만, DynamicAttribute는 적용되지 않는데, 그 변수의 사용이 메소드 내로 제한되기 때문이다. dynamic은 실제 object와 같기 때문에, 여러분은 오직 dynamic과 object로 구분되는 함수 명세를 작성할 수 없다. 모든 표현식은 암묵적으로 dynamic으로 캐스트될 수 있는데 모든 표현식의 결과는 Object에서 파생된 타입이기 때문이다. 보통 컴파일러는 Object에서 다른 타입으로 표현식을 암묵적으로 캐스트하는 것을 허용하지 않는다. 여러분은 반드시 명시적 캐스트 문법을 사용해야 한다. 하지만, 컴파일러는 표현식을 dynamic에서 다른 타입으로 캐스팅하는 것은 암시적 캐스트 문법을 사용하여 허용한다.
dynamic 표현식은 정말로 System.Object와 같은 타입이다. 컴파일러는 여러분이 그 표현식에 어떤 연산을 시도하든지 모두 합법으로 간주하므로, 컴파일러는 어떠한 경고나 에러를 발생시키지 않을 것이다. 하지만 여러분이 유효하지 않은 연산을 수행한다면 런타임시에 예외가 발생할 것이다. 추가로 Visual Studio는 어떠한 IntelliSense 지원을 할 수 없다. 여러분은 Object를 확장시키는 메소드를 정의할 수는 있지만 dynamic을 확장시키는 확장 메소드는 정의할 수 없다. 그리고 여러분은 dynamic 메소드 호출에 람다 표현식 혹은 익명 메소드를 인자로 넘길 수 없는데, 컴파일러가 사용되는 타입을 추론할 수 없기 때문이다. Chapter 6 타입과 멤버 기본 4장과 5장에서 나는 타입과 모든 타입의 모든 인스턴스에 존재함을 보장하는 연산이 무엇인지에 중점을 두었다. 나는 또한 모든 타입들이 참조타입과 값타입 2개의 범주중의 하나에 속한다는 것을 설명했다. 이번 장과 다음 장에서는 하나의 타입에서 정의될 수 있는 서로 다른 종류의 멤버들을 사용하여 타입을 설계하는 방법을 보여줄 것이다. 7장부터 11장 까지에서는, 다양한 멤버들을 자세하게 논의할 것이다. 타입 멤버의 종류 타입은 다음과 같은 종류의 멤버들을 0개 이상 정의할 수 있다.
타입 가시성(Visibility) 타입을 파일 범위에서 정의할 때, 여러분은 타입의 가시성을 public 혹은 internal 중의 하나로 명시할 수 있다. 프렌드 어셈블리(Friend Assembly) CLR과 C#은 프렌드 어셈블리를 지원하는데, 이 특징은 여러분이 다른 어셈블리 안에 존재하는 internal 타입에 대해 단위 테스트를 수행하는 코드를 포함하는 또 다른 어셈블리를 가지기 원할 때 유용하다. 어떤 어셈블리를 빌드할 때, System.Runtime.CompilerServices 네임스페이스에 정의된 InternalsVisibleTo 어트리뷰트를 사용하여 다른 어셈블리를 "친구"로 간주하게 지시할 수 있다. 이 어트리뷰트는 문자열 파라미터를 가지는데, 이 문자열은 프렌드 어셈블리의 이름과 공용키를 나타낸다. 프렌드 어셈블리는 해당 어셈블리의 모든 internal 타입 뿐만 아니라 그 타입의 internal 멤버까지 접근할 수 있다. 멤버 접근성(Accessibility)
파생 클래스가 자신의 기반 클래스에 정의된 멤버를 재정의할 때, C# 컴파일러는 원래 멤버와 재정의하는 멤버가 동일한 접근성을 가질 것을 요구한다. 즉, 기반 클래스의 멤버가 protected이면, 파생 클래스의 재정의하는 멤버 또한 protected이어야 한다. 하지만, 이것은 C#의 제약사항이지, CLR의 제약사항이 아니다. 기반 클래스로부터 파생할 때, CLR은 멤버의 가시성이 더 제한적이 되는 것이 아닌 덜 제한적이 되도록 요구한다. 예를 들어, 클래스는 기반 클래스에 protected로 정의되어 있는 메소드를 public으로 재정의할 수 있다. 하지만 private으로 재정의할 수는 없다. 정적 클래스 정적 클래스는 사실 연관된 메소드들을 함께 묶는 단순한 수단이다. C#은 static 키워드를 사용하여 인스턴스화 할 수 없는 클래스를 정의할 수 있게 해준다. 이 키워드는 오직 클래스에만 적용될 수 있는데, C#은 구조체(값타입)이 항상 인스턴스화 될 수 있게 해주기 때문이다. 컴파일러는 정적 클래스에 많은 제약 사항들을 둔다.
부분 클래스, 구조체, 그리고 인터페이스 partial 키워드는 C# 컴파일러에게 단일 클래스, 구조체 혹은 인터페이스 정의가 하나 이상의 소스코드 파일에 퍼져 있을 수 있음을 말하는 것이다. 컴파일러는 한 타입의 부분들을 컴파일 시간에 모두 함께 묶는다. 컴포넌트, 다형성 그리고 버전관리 C#은 컴포넌트의 버전관리에 영향을 주는 타입과 타입 멤버에 적용될 수 있는 5개의 키워드를 제공한다.
CLR이 가상 메소드, 속성, 이벤트를 호출하는 방법 이들 모든 메소드들(정적 메소드, 비가상 인스턴스 메소드, 가상 인스턴스 메소드)을 호출하는 코드가 작성될 때, 호출 코드를 만드는 컴파일러는 그 메소드 정의의 플래그들을 조사하여 호출이 올바르게 만들어지도록 하기 위해 올바른 IL 코드를 만드는 방법을 결정한다. CLR은 메소드 호출을 위해 2개의 IL 명령어를 제공한다.
타입 가시성과 멤버 접근성을 똑똑하게 사용하기 타입을 버전관리 할때 가상 메소드로 처리하기 Chapter 7 상수와 필드 이번 장은 여러분에게 타입에 데이터 멤버를 추가하는 방법을 보여준다. 특히, 우리는 상수와 필드를 살펴볼 것이다. 상수(Constants) 상수는 절대 변하지 않는 값을 가지는 심볼이다. 상수 심볼을 정의할 때, 그 값은 컴파일 타임에 결정될 수 있는 값이어야 한다. 그러면 컴파일러는 그 상수의 값을 어셈블리 메타데이터 안에 저장한다. 이는 여러분이 컴파일러가 기본타입으로 간주하는 타입만을 상수로 정의할 수 있음을 의미한다. C#에서 다음의 타입들이 기본타입이고 상수로 사용될 수 있다: Boolean, Char, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, Single, Double, Decimal, String. 하지만 C#는 또한 여러분이 그 값을 null로 설정한다면 비-기본타입도 상수로 정의할 수 있도록 해준다.
상수값은 절대 변하지 않기 때문에, 상수는 항상 타입을 정의하는 부분으로 간주된다. 즉, 상수는 항상 정적 멤버로 간주되지, 인스턴스 멤버로 간주되지 않는다. 상수 정의는 메타데이터 생성을 유발시킨다.
위 예제는 여러분에게 버전관리 문제를 명백하게 보여준다. 만약 개발자가 MaxEntriesInList 상수를 1000으로 변경하고 오직 DLL 어셈블리만 재빌드를 한다면, 애플리케이션 어셈블리는 영향을 받지 않는다. 애플리케이션이 새로운 값을 얻으려면, 그 애플리케이션 또한 재빌드되어야 한다. 컴파일시가 아닌 런타임시에 다른 어셈블리로부터 값을 가져올 필요가 있다면, 여러분은 상수를 사용하면 안된다. 대신에 readonly 필드를 사용할 수 있다. 필드(Fields) 필드는 값타입의 인스턴스 또는 참조타입에 대한 참조를 담고 있는 데이터 멤버이다. 다음은 필드에 적용될 수 있는 수정자를 보여준다.
타입 필드에서, 그 필드의 데이터를 유지하는데 필요한 동적 메모리는 타입 객체 안에 할당되는데, 그 타입 객체는 타입이 AppDomain 안으로 로딩될 때 생성되고, 이는 그 타입을 참조하는 메소드가 첫번째로 JIT 컴파일될 때 발생한다. 인스턴스 필드에서, 그 필드의 데이터를 유지하는 동적 메모리는 그 타입의 인스턴스가 구성될 때 할당된다. 컴파일러와 검증기능은 readonly 필드가 생성자가 아닌 다른 메소드에서는 쓰여지지 않음을 보장한다. 리플렉션은 readonly 필드를 수정하는데 사용될 수 있다. 어떤 필드가 참조타입이고 readonly로 표시되어 있다면, 그것은 참조가 불변하는 것이지 그 필드가 가리키는 객체가 불변하는 것이 아니다. 다음 코드를 보자.
Chapter 8 메소드(Methods) 이번 장은 여러분이 맞닥뜨리게 될 다양한 종류의 메소드들에 중점을 둔다. 우리는 또한 확장 메소드도 얘기할 것인데, 이는 이미 존재하는 타입에 여러분 자신만의 인스턴스 메소드를 논리적으로 추가할 수 있도록 해준다. 또한 부분 메소드도 있는데, 이는 타입의 구현부를 여러 부분으로 나눌 수 있도록 해준다. 인스턴스 생성자와 클래스(참조 타입) 참조타입의 인스턴스가 생성될 때, 인스턴스의 데이터 필드를 위해 메모리가 할당되는데, 객체의 오버헤드 필드(타입 객체 포인터와 동기화 블록 인덱스)가 초기화된 후, 그 객체의 초기 상태를 설정하기 위해 그 타입의 인스턴스 생성자가 호출된다. 참조타입 객체를 생성할 때, 그 객체를 위해 할당되는 메모리는 타입의 인스턴스 생성자가 호출되기 전에 항상 0으로 설정된다. 생성자가 명시적으로 덮어쓰지 않는 모든 필드들은 0 혹은 null값을 가짐을 보장한다. 만약 여러분이 클래스를 정의할 때 어떠한 생성자도 명시적으로 정의하지 않는다면, C# 컴파일러는 여러분을 위해 기본 생성자(파라미터가 없는)를 정의하는데, 이 생성자는 단순히 기반 클래스의 기본 생성자를 호출한다. 몇몇 경우에, 타입의 인스턴스는 인스턴스 생성자가 호출되지 않고 생성될 수 있다. 특히, 객체의 MemerwiseClone 메소드 호출은 메모리를 할당하고 그 객체의 오버헤드 필드들을 초기화한 후, 원본 객체의 바이트들을 새로운 객체로 복사한다. 또한 객체가 런타임 serializer로 역직렬화될 때 생성자는 보통 호출되지 않는다. 역직렬화 코드는 System.Runtime.Serialization.FormatterService 타입의 GetUninitializedObject 혹은 GetSafeUninitializedObject 메소드를 사용하여 생성자 호출없이 그 객체를 위한 메모리를 할당한다. 생성자 내에서 객체가 생성되는데 영향을 줄 수 있는 가상 메소드를 호출해서는 안된다. 그 이유는 만약 인스턴스화 되는 타입 안에서 가상 메소드가 재정의된다면, 재정의된 메소드의 파생된 타입의 구현부가 실행되지만 계층도의 모든 필드들이 완전히 초기화되지 않기 때문이다. 그러므로 가상 메소드의 호출은 예상치 못한 동작을 초래할 수 있다. C#은 타입의 인스턴스가 생성될 때 참조 타입 내에 정의된 필드들의 초기화를 허용하는 간단한 문법을 제공한다.
위 코드의 SomeType의 생성자는 m_x에 5를 저장한 후 기반 클래스의 생성자를 호출한다. 즉 C# 컴파일러는 인스턴스 필드를 인라인으로 초기화할 수 있는 편리한 문법을 제공하고 이를 생성자 메소드로 옮긴다. 이는 여러분이 코드 증가의 위험성을 알고 있어야 함을 의미한다.
컴파일러가 3개의 생성자 메소드를 위한 코드를 만들 때, 각 메소드의 시작에는 m_x, m_s, m_d를 초기화하는 코드를 포함시킨다. 이 초기화 코드 후에 컴파일러는 기반 클래스의 생성자를 호출하는 코드는 집어넣은 후, 생성자 메소드 내에 나타나는 코드들을 추가한다. 위 클래스에서는 3개의 생성자가 있기 때문에, m_x, m_s, m_d를 초기화하는 코드가 3번이나 발생하는데, 각 생성자마다 하나씩이다. 다음은 이를 방지하는 기법이다.
인스턴스 생성자와 구조체(값타입) 값타입 생성자는 참조타입의 생성자와는 꽤 다르게 동작한다. CLR은 항상 값타입 인스턴스의 생성을 허용하는데, 값타입이 인스턴스화되는 것을 막을 방법이 없다. 이런 이유로, 값타입은 사실 타입 내에 정의된 생성자를 가질 필요가 없고, C# 컴파일러는 값타입에 대한 파라미터가 없는 기본 생성자를 만들어내지 않는다. CLR은 여러분이 값타입에 대한 생성자를 정의하도록 허락한다. 이들 생성자가 실행되는 유일한 방법은 여러분이 그 생성자들 중 하나를 명시적으로 호출하는 코드를 작성할 때이다.
위에 정의된 Point 값타입에는 기본 생성자가 정의되어 있지 않다. 다음과 같이 코드를 재작성하고, 새로운 Rectangle 인스턴스를 생성하면, m_topLeft, m_bottomRight 필드안의 m_x와 m_y는 0으로 초기화될까 아니면 5로 초기화될까?
많은 개발자들(특히 C++ 출신 개발자들)은 C# 컴파일러가 Rectangle의 생성자 안에 Rectangle의 두 필드를 위해 Point의 파라미터가 없는 기본 생성자를 자동으로 호출하는 코드를 넣을 것이라고 기대한다. 하지만 애플리케이션의 런타임 성능을 개선하기 위해, C# 컴파일러는 그런 코드를 자동으로 넣지 않는다. 사실 많은 컴파일러는 값타입의 기본 생성자를 자동으로 호출하는 코드를 결코 생성하지 않는데, 값타입이 기본 생성자를 제공한다 할지라도 그렇다. 값타입의 파라미터가 없는 기본 생성자가 호출되도록 하려면, 개발자는 값타입의 생성자를 호출하는 명시적인 코드를 추가해야만 한다. C#은 값타입이 파라미터가 없는 생성자를 정의하도록 허락하지 않는다. 그래서 이전 코드는 실제 컴파일되지 않는다. C#은 생성자가 호출되는 시점에 대해 개발자가 가질지도 모르는 혼란을 제거하기 위해 값타입이 파라미터 없는 생성자를 정의하는 것을 불허한다. 생성자가 정의될 수 없다면 컴파일러는 그것을 자동으로 호출하는 코드를 결코 발생시킬 수 없다. 파라미터 없는 생성자 없이, 값타입의 필드들은 항상 0/null로 초기화된다. 엄격히 말하면, 값타입은 자신이 참조타입 안에 내장된 필드일 때 그 값타입의 필드들이 0/null 임을 보장받는다. 스택 기반의 값타입 필드들은 0/null 을 보장받지 못한다. 검증성을 위해, 모든 스택 기반 값타입 필드는 읽히기 전에 반드시 기록되어져야 한다. 만약 코드가 값타입의 필드가 기록되기 전에 읽혀진다면, 보안 침범의 가능성이 있다. 비록 C#은 파라미터 없는 생성자를 가지는 값타입을 허용하지 않지만, CLR은 그렇게 할 수 있음을 명심하라. C#은 파라미터 없는 생성자를 가지는 값타입을 허용하지 않기 때문에, 다음과 같은 타입의 컴파일은 에러를 발생시킨다.
또한, 검증가능 코드는 모든 필드가 읽혀지기 전에 모든 필드는 기록되어저야 함을 요구하기 때문에, 값타입에 대해 여러분이 가지는 모든 생성자들은 그 타입의 모든 필드들을 초기화해야 한다.
값타입의 모든 필드들을 초기화하는 다른 방법으로, 다음과 같이 할 수 있다.
타입 생성자 인스턴스 생성자 뿐만 아니라, CLR은 타입 생성자(정적 생성자, 클래스 생성자 혹은 타입 초기화자)도 지원한다. 타입 생성자는 인터페이스(비록 C#은 허용하지 않지만), 참조타입, 그리고 값타입에 적용될 수 있다. 여러분은 타입 생성자를 정의할 수 있는데, 파라미터 없는 기본 생성자에 static을 추가로 표시하면 된다. 또한 타입 생성자는 항상 private이 되어야 한다. C#은 자동으로 타입 생성자를 private으로 만들어준다. 사실 여러분이 명시적으로 타입 생성자에 private을 표시해주면, C# 컴파일러는 에러를 발생시킨다. 타입 생성자는 private이 되어서 개발자가 작성한 코드가 이들을 호출하는 것을 방지해준다. CLR은 항상 타입 생성자를 호출할 수 있다. 비록 여러분은 값타입 내에 타입 생성자를 정의할 수는 있지만, 여러분은 그렇게 하면 절대 안된다. 왜냐하면 CLR이 값타입의 정적 타입 생성자를 호출하지 않는 경우가 있기 때문이다. 예를 들면 다음과 같다.
CLR은 타입 생성자가 AppDomain당 오직 한번만 실행되기를 원한다. 이것을 보장하기 위해 타입 생성자가 호출될 때, 호출하는 스레드는 상호 배타적인 스레드 동기화 잠금을 획득한다. 그래서 만약 여러 스레드들이 동시에 타입 생성자를 호출하려 시도해도, 오직 하나의 스레드만이 잠금을 획득하고 나머지 스레드들은 블록된다. 첫번째 스레드가 생성자를 떠나면, 나머지 기다리던 스레드들은 깨어나서 그 생성자 코드가 이미 수행되었음을 알게 된다. 이들 스레드들은 그 코드를 다시 수행하지 않고 그냥 반환된다. 사실, CLR이 타입 생성자를 호출하는 책임을 가지기 때문에, 여러분은 타입 생성자들이 특정 순서로 호출되기를 바라는 코드를 작성해서는 안된다. 타입 생성자 내의 코드는 오직 타입의 정적 타입만을 접근할 수 있기 때문에, 타입 생성자의 일반적인 목적은 이들 필드들을 초기화하는것이다. 인스턴스 필드의 경우와 마찬가지로, C#은 타입의 정적 필드들을 초기화할 수 있는 간단한 문법을 제공한다.
연산자 오버로드 메소드 여러분이 선택한 프로그래밍 언어에 따라 연산자 오버로딩의 지원 여부와 문법 형태가 결정된다. 여러분의 소스코드를 컴파일할 때, 컴파일러는 연산자의 행동을 나타내는 메소드를 생산한다. CLR 명세는 연산자 오버로드 메소드는 반드시 public이고 static이어야 함을 규정한다. 추가로 C#은 그 연산자 메소드 파라미터 중의 최소한 하나는 연산자 메소드가 정의된 타입과 같아야 함을 요구한다. 이 제약사항의 이유는 그래야만 C# 컴파일러가 합리적 시간 안에 연결된 연산자 메소드를 찾을 수 있기 때문이다. 다음은 C#이 오버로드를 지원하는 단항와 이항 연산자 집합이다.
변환 연산자 메소드 변환 연산자는 한 타입에 대한 어떤 객체를 다른 타입으로 변환시키는 메소드이다. 여러분은 특별한 문법을 사용하여 변환 연산자를 정의할 수 있다. CLR 명세는 변환 연산자가 public이고 static 메소드이어야 함을 규정한다. 추가로 C#은 파라미터 혹은 반환값이 변환 메소드가 정의된 타입과 동일한 타입이어야 함을 요구한다. 다음 코드는 Rational 타입에 4개의 변환 연산자 메소드를 추가한다.
확장 메소드 C#의 확장 메소드는 여러분이 인스턴스 메소드 문법을 사용하여 정적 메소드를 호출할 수 있게 해준다.
이제 컴파일러가 다음과 같은 코드를 보면, 컴파일러는 먼저 StringBuilder 클래스 혹은 이것의 기반 클래스가 단일 Char 파라미터를 취하는 IndexOf 인스턴스 메소드를 제공하는지를 검사한다.
만약 일치하는 인스턴스 메소드를 찾지 못하면, 컴파일러는 그 메소드를 호출하는데 사용된 표현식의 타입과 일치하는 타입을 첫번째 파라미터로 취하는 IndexOf 이름의 정적 메소드를 정의한 모든 정적 클래스를 찾는다. 이 타입은 또한 this 키워드로 표시되어 있어야 한다. 규칙과 가이드라인
확장 메소드로 다양한 타입들을 확장시키기 확장 메소드는 정적 메소드의 호출이기 때문에, CLR은 메소드를 호출하는데 사용된 표현식의 값이 null이 아닌지를 확인하지 않는다. 여러분은 인터페이스를 위한 확장 메소드를 정의할 수 있다.
여러분은 또한 델리게이트 타입을 위해 확장 메소드를 정의할 수도 있다.
여러분은 또한 열거형 타입에도 확장 메소드를 추가할 수 있다. 마지막으로, C# 컴파일러는 여러분이 한 객체에 대해 확장 메소드를 가리키는 델리게이트를 생성할 수 있도록 해준다.
Extension 어트리뷰트 C#에서 여러분이 정적 메소드의 첫번째 파라미터를 this 키워드로 표시하면, 컴파일러는 내부적으로 그 메소드에 커스텀 어트리뷰트를 적용하고, 그 어트리뷰트는 메타데이터 안에 영속적으로 저장된다. 그 어트리뷰트는 System.Core.dll 어셈블리에 정의되어 있고, 다음과 비슷하다.
부분 메소드(Partial Method)
위 코드에는 2가지 문제점이 존재한다.
C#의 부분 메소드 특징은 여러분에게 앞에서 다룬 문제점들을 해결함과 동시에 동작 혹은 타입을 재정의할 수 있게 해준다. 다음의 코드는 부분 메소드를 사용하여 이를 해결함을 보여준다.
위 새로운 코드에 대해 알아야 할 몇가지가 있다.
부분 메소드를 사용할 때의 또 다른 큰 이점이 있다. 만약 여러분이 툴이 생성한 코드만을 컴파일 한다면, 컴파일러는 다음과 같은 코드와 같은 IL 코드와 메타데이터를 생산한다.
즉, 부분 메소드 선언에 대한 어떠한 구현도 없다면, 컴파일러는 부분 메소드를 표현하는 어떠한 메타데이터도 생산하지 않는다. 또한 컴파일러는 부분 메소드를 호출하는 어떠한 IL 코드도 생산하지 않는다. 그리고 부분 메소드에 넘겨지는 어떠한 인자도 평가하는 코드도 생산하지 않는다. 그 결과는 메타데이터/IL 코드량이 줄어들며, 런타임 성능이 매우 좋아진다. 규칙과 가이드라인
Chapter 9 파라미터 이번 장은 메소드에 파라미터를 넘기는 다양한 방법들에 중점을 두는데, 선택적으로 파라미터를 명시하거나, 이름으로 파라미터를 명시하거나, 변경될 수 있는 인자의 수를 받는 메소드를 정의하는 것 뿐만 아니라 참조로 파라미터를 넘기는 방법들을 살펴본다. 선택적 그리고 이름있는 파라미터 규칙과 가이드라인 DefaultParameterValue과 Optional 어트리뷰트 C#에서, 여러분이 파라미터에 기본값을 주면, 컴파일러는 내부적으로 System.Runtime.InteropServices.OptionalAttribute 커스텀 어트리뷰트를 그 파라미터에 적용시키고, 이 어트리뷰트는 결과 파일의 메타데이터에 저장된다. 또한 컴파일러는 System.Runtime.InteropServices.DefaultParameterValueAttribute를 그 파라미터에 적용시키고, 메타데이터에 저장한다. 그런 후에, DefaultParameterValueAttribute의 생성자에 여러분의 소스코드에 여러분이 명시한 상수값이 넘겨진다. 암묵적으로 타입이 주어지는 지역 변수 메소드에 참조로 파라미터를 넘기기 기본적으로 CLR은 모든 메소드 파라미터들은 값으로 넘겨진다고 가정한다. 참조 타입 객체가 넘겨질 때, 그 객체에 대한 참조(혹은 포인터)가 그 메소드로 (값으로) 넘겨진다. 이는 그 메소드가 그 객체를 수정할 수 있고 호출자는 그 변경사항을 볼 수 있음을 의미한다. 값 타입 인스턴스에 대해서는, 그 인스턴스의 복사본이 메소드로 넘겨진다. 이는 그 메소드는 값 타입의 사적 복사본을 얻는 것이고 호출자 안의 인스턴스에는 영향을 주지 않음을 의미한다. CLR은 여러분이 파라미터들을 값에 의해서가 아닌 참조에 의해서 넘길 수 있도록 해준다. C#에서, 여러분은 out과 ref 키워드를 사용하여 이것을 할 수 있다. CLR의 관점에서 보자면, out과 ref는 동일하다. 즉 여러분이 어떠한 키워드를 사용하든지 관계없이 동일한 IL 코드가 생성되고, 메타데이터 또한 1비트를 제외하고는 동일한데, 그 1비트는 여러분이 메소드를 선언할 때 out을 사용했는지 아니면 ref를 사용했는지를 기록한다. 하지만 C# 컴파일러는 이 2개의 키워드를 다르게 취급하는데, 그 차이는 어떤 메소드가 그 언급된 객체의 초기화에 책임이 있는지에 관련이 있다. 만약 메소드의 파라미터가 out으로 표기되었다면, 호출자는 그 메소드를 호출하기 전에 그 객체를 초기화할 필요가 없다. 호출된 메소드는 그 값을 읽을 수 없으며, 반환하기 전에 반드시 기록해야만 한다. 만약 메소드의 파라미터가 ref로 표기되었다면, 호출자는 메소드를 호출하기 전에 파라미터의 값을 초기화해야만 한다. 호출된 메소드는 그 값을 읽을 수 있고 쓸 수도 있다. 2개의 참조 타입을 스왑하는 메소드를 구현하기 위해 ref 키워드를 사용하는 예제를 살펴보자.
두개의 String 객체에 대한 참조를 스왑하기 위해, 여러분은 아마도 다음과 같은 코드를 작성할 수도 있을 것이다.
하지만 이 코드는 컴파일되지 않는다. 메소드에 참조로 넘겨지는 변수는 메소드 서명에 선언된 타입과 같아야 하기 때문이다. 즉, Swap은 2개의 Object 참조를 원하는 것이지, 2개의 String 참조를 바라는 것이 아니다. 여러분이 제네릭을 사용하여 이 문제를 해결할 수 있다.
메소드에 변하는 인자의 수를 넘기기 변하는 수의 인자들을 받는 메소드를 선언하려면, 다음과 같이 메소드를 선언하면 된다.
params 키워드는 컴파일러에게 해당 파라미터에 System.ParamArrayAttribute 커스텀 어트리뷰트의 인스턴스를 적용시키라고 일러준다. C# 컴파일러가 메소드에 대한 호출을 만났을 때, 컴파일러는 명시된 이름을 가지는 모든 메소드들 중에서 ParamArray 어트리뷰트가 적용되지 않은 파라미터를 가지는 것들을 확인한다. 만약 그 호출을 받을 수 있는 메소드가 존재한다면, 컴파일러는 그 메소드를 호출하는데 필요한 코드를 만든다. 하지만 컴파일러가 일치하는 메소드를 찾을 수 없다면, 해당 호출을 만족시키는지 보기 위해 ParamArray 어트리뷰트를 가지는 메소드를 찾는다. 만약 컴파일러가 일치하는 메소드를 찾는다면, 선택된 메소드를 호출하는 코드를 만들기 전에 배열을 만들고 각 요소를 넣는 코드를 발생시킨다. 변하는 인자 수를 취하는 메소드를 호출하는 것은 만약 명시적으로 null을 넘기지 않는 한 추가적인 성능 부하를 일으킬 수 있음을 명심하라. 배열 객체가 관리힙에 할당되어야 하고, 배열의 요소들이 초기화되어야 하고, 배열의 메모리가 결국엔 가비지 콜렉트되어야 하기 때문이다. 이와 연관된 성능 부하를 줄이기 위해서, 여러분은 params 키워드를 사용하지 않는 몇몇 오버로드된 메소드들을 정의하는 것을 고려할 수 있다. 파라미터와 반환값 가이드라인 메소드의 파라미터 타입을 선언할 때, 여러분은 가능한 한 가장 약한 타입을 명시해야 하는데, 기반 클래스 보다는 인터페이스를 선호해야 한다. 예를 들어, 아이템 콜렉션을 다루는 메소드를 작성한다면, List<T>와 같은 강한 데이터 타입 혹은 ICollection<T> 아니면 IList<T>와 같은 강한 인터페이스 타입보다는 IEnumerable<T>과 같은 인터페이스를 사용하는 것이 가장 좋다. 반면에, 메소드의 반환 타입은 가능한 한 가장 강한 타입을 사용하여 선언하는 것이 일반적으로 가장 좋다. 예를 들어 Stream 객체를 반환하는 것 대신에 FileStream 객체를 반환하는 메소드를 선언하는 것이 더 좋다. 상수성(Const-ness) Chapter 10 속성 이번 장에서 나는 속성에 대해 얘기할 것이다. 속성은 소스 코드가 간단한 문법으로 메소드를 호출할 수 있도록 해준다. CLR은 2종류의 속성을 제공한다: 파라미터 없는 속성(간단히 속성)과 파라미터 있는 속성(이는 다른 언어에서 서로 다르게 부른다. 예를 들어 C#에서는 이를 인덱서라 부른다). 나는 또한 객체와 콜렉션 초기화자를 사용하여 속성을 초기화하는 것에 대해 얘기할 것이고, 또한 C#의 익명 타입과 System.Tuple 타입을 사용하여 많은 속성들을 함께 묶는 방법들을 얘기할 것이다. 파라미터 없는 속성(Parameterless Properties) 여러분은 속성을 똑똑한 필드, 즉 필드 뒤에 추가적인 로직을 가지는 필드로 생각할 수 있다. CLR은 정적, 인스턴스, 추상 그리고 가상 속성을 지원한다. 추가로, 속성은 접근성 수정자로 표시될 수도 있고 인터페이스 안에 정의될 수도 있다. 속성의 get/set 메소드가 타입 내에 정의된 사적 필드를 조작하는 것은 매우 흔하다. 이 필드는 일반적으로 지원 필드(backing field)라고 불린다. 하지만 get과 set 메소드는 이 지원 필드를 접근할 필요는 없다.
자동 구현 속성(Automatically Implemented Properties, AIP) 만약 여러분이 지원필드를 단순히 은닉하기 위해 속성을 생성하고자 한다면, C#은 AIP로 알려진 간편화된 문법을 제공한다.
지능적으로 속성을 정의하기 객체와 콜렉션 초기화자(Initializer) 객체를 생성한 후 객체의 공용 속성들의 값을 설정하는 것은 흔한 일이다. 이 흔한 프로그래밍 패턴을 간소화하기 위해, C#은 특별한 객체 초기화 문법을 제공한다.
위 코드는 다음과 같은 IL 코드와 동일하다.
만약 속성 타입이 IEnumerable 혹은 IEnumerable<T> 인터페이스를 구현한다면, 그 속성은 콜렉션으로 간주되고, 콜렉션 초기화는 대체 연산이 아닌 추가 연산이 된다.
위 코드를 컴파일 할 때, 컴파일러는 Students 속성이 List<String> 타입이고 이 타입은 IEnumerable<String> 인터페이스를 구현한다는 것을 알게 된다. 이제 컴파일러는 List<String> 타입이 Add 메소드를 제공한다고 가정한다. 그러면 컴파일러는 콜렉션의 Add 메소드를 호출하는 코드를 발생시킨다.
어떤 콜렉션의 Add 메소드는 여러 인자들을 취한다. 예를 들어 Dictionary의 Add 메소드는 다음과 같다.
여러분은 콜렉션 초기화자 안에서 중첩 중괄호를 사용하여 Add 메소드에 여러 인자들을 넘길 수 있다.
익명 타입(Anonymous Type) C#의 익명 타입은 여러분이 매우 간단하고 간결한 문법을 사용하여 불변의 튜플 타입을 자동으로 선언할 수 있도록 해준다. 튜플 타입은 서로서로 관련된 속성의 집합을 포함하는 타입이다. 여러분이 다음과 같은 코드를 작성하면,
컴파일러는 각 표현식이 타입을 추론하고, 그 추론된 타입의 사적 필드를 생성한 후, 각 필드의 공용 읽기 전용 속성을 만든 다음, 모든 표현식을 받는 생성자를 생성한다. 생성자 코드는 자신에게 넘겨진 표현식 결과들로부터 사적 읽기 전용 필드들을 초기화한다. 추가로, 컴파일러는 Object의 Equals, GetHashCode, ToString 메소드들을 재정의한다. 컴파일러는 익명 타입들을 정의함에 있어서 매우 똑똑하다. 만약 컴파일러가 동일한 구조를 가지는 여러 익명 타입들을 본다면, 컴파일러는 그 익명 타입에 대해 오직 하나의 정의만을 생성하고, 그 타입에 대해 여러 인스턴스들을 생성한다. "동일한 구조"란, 같은 타입과 이름을 가지고 동일한 순서로 명시됨을 의미한다. 타입의 동일성 때문에, 우리는 익명 타입의 암묵적 타입 배열을 생성할 수 있다.
익명 타입의 인스턴스는 메소드 밖으로 유출되어서는 안된다. 메소드는 익명 타입을 파라미터로 받을 수 없는데, 익명 타입을 명시할 방법이 없기 때문이다. 이와 유사한 이유로, 메소드는 익명 타입에 대한 참조를 리턴할 수 없다. 비록 익명 타입의 인스턴스를 Object로 취급할 수는 있지만, 타입 Object의 변수를 익명 타입으로 캐스트할 수 없는데, 여러분은 컴파일 시에 익명 타입의 이름을 알 수 없기 때문이다.
System.Tuple 타입 익명 타입과 같이, Tuple이 생성된 후에 이것은 불변이다(모든 속성들은 읽기 전용이다). Tuple 클래스는 ComareTo, Equals, GetHashCode, ToString 메소드 뿐만 아니라 Size 속성도 제공한다. 추가로 모든 Tuple 타입은 IStructuralEquatable, IStructuralComparable, 그리고 IComparable 인터페이스도 구현하는데, 2개의 Tuple 객체를 비교하여 각각의 필드를 서로 비교할 수 있다. 파라미터가 있는 속성(Parameterful Properties) C#에서, 파라미터가 있는 속성(인덱서)는 배열과 같은 문법을 사용하여 노출된다. 즉, 여러분은 인덱서를 C# 개발자가 []연산자를 오버로드하는 방식으로 생각할 수 있다. C#이 인덱서를 표현하는 문법으로서 this[...]을 요구한다는 사실은 순전히 C# 팀에 의해 만들어진 선택이다. 이 선택이 의미하는 바는 C#은 인덱서가 오직 객체의 인스턴스 상에서만 정의될 수 있다는 것이다. C#은 개발자가 정적 인덱서 속성을 정의할 수 있도록 해주지 않는데, CLR은 정적 인덱서 속성을 지원한다. 컴파일러는 인덱서 이름에 get_과 set_를 붙임으로서 자동으로 이들 메소드의 이름을 발생시킨다. 인덱서에 대한 C# 문법은 개발자가 인덱서 이름을 명시하도록 허락하지 않기 때문에, C# 컴파일러 팀은 접근자 메소드를 사용하는 기본 이름을 선택해야만 했고, 그들은 Item을 선택했다. 그래서 컴파일러에 의해 생기는 메소드 이름은 get_Item과 set_Item이다. 여러분이 C#에서 프로그래밍할 때는, 결코 Item이라는 이름을 볼 수 없으므로, 여러분은 컴파일러가 선택한 그 이름을 보통은 신경쓸 필요가 없다. 하지만 여러분이 다른 프로그래밍 언어에서 사용될 타입에 대한 인덱서를 디자인할 때는, 여러분의 인덱서에 주어질 기본 이름인 Item을 바꾸기를 원할 수도 있다. C#은 System.Runtime.CompilerServies.IndexerNameAttribute 커스텀 어트리뷰트를 인덱서에 적용하여 이 이름을 변경할 수 있도록 해준다.
속성 접근자 메소드 호출 성능 간단한 get과 set 접근자 메소드에 대해, JIT 컴파일러는 그 코드를 인라인하기 때문에, 필드 대신에 속성을 사용함에 있어서 런타임 성능 하락은 없다.
속성 접근자 접근성 제네릭 속성 접근자 메소드 C#은 속성이 자신만의 제네릭 타입 파라미터를 정의할 수 없도록 한다. 그 이유는 그것이 개념적으로 의미가 없기 때문이다. 속성은 질의되거나 혹은 설정될 수 있는 객체의 특성을 표현하는 것이다. 제네릭 타입 파라미터 도입은 질의/설정의 동작이 변경될 수 있음을 의미하는 것인데, 개념적으로 속성은 동작을 가지지 않는다. Chapter 11 이벤트 이번 장에서, 나는 타입이 정의할 수 있는 마지막 종류의 멤버인 이벤트에 대해 얘기할 것이다. 이벤트 멤버를 정의하는 타입은 그 타입이(혹은 타입의 인스턴스가) 다른 객체에게 뭔가 특별한 일이 일어났음을 알려줄 수 있도록 해준다. 이벤트 멤버를 정의하는 것은 타입이 다음과 같은 기능을 제공함을 의미한다.
CLR 이벤트 모델은 델리게이트에 기반을 두고 있다. 델리게이트는 콜백 메소드를 호출하는 타입에 안전한 방법이다. 콜백 메소드는 객체들이 자신이 구독한 통지를 받는 수단이다. 이벤트를 노출시키는 타입을 설계하기 단계 #1: 이벤트 통지 수신자에게 전송되어야 하는 부가 정보를 가지는 타입을 정의한다 관례상, 이벤트 핸들러에게 건네지는 이벤트 정보를 담고 있는 클래스는 System.EventArgs으로부터 파생되어야 하고, 그 클래스의 이름은 접미사로 EventArgs를 가져야 한다.
단계 #2: 이벤트 멤버를 정의한다 이벤트 멤버는 C# 키워드 event를 사용하여 정의된다. 각각의 이벤트 멤버는 접근자(거의 항상 public일 것이다), 델리게이트의 타입(호출될 메소드의 원형을 가리킨다), 그리고 이름이 주어진다.
제네릭 System.EventHandler 델리게이트는 다음과 같이 정의되어 있기 때문에,
메소드 원형은 다음과 같이 되어야 한다.
단계 #3: 등록된 객체에 이벤트가 발생했음을 알려주기 위해 이벤트를 발생시키는 메소드를 정의한다
스레드에 안전한 방식으로 이벤트를 발생시키기 .NET 프레임워크가 나왔을 때, 개발자가 이벤트를 발생시키기 위해 권장되는 방식은 다음과 같았다.
이 메소드의 문제점은 이 스레드는 NewMail을 null로 보지 않은 후 NewMail을 호출하기 전에, 다른 스레드가 체인으로부터 델리게이트를 제거하여 NewMail을 null로 만들 수가 있는데, 그러면 NullReferenceExceptin이 던져진다. 이런 경쟁조건을 해결하기 위해, 많은 개발자들이 다음과 같은 코드를 작성했다.
이 메소드는 NewMail에 대한 참조를 임시 변수 temp에 복사하여 할당이 수행된 시점의 델리게이트 체인을 가리키게 만든다. 이제 이 메소드는 temp와 null을 비교하고 temp를 호출하므로, 만약 다른 스레드가 NewMail이 temp에 할당된 후에 NewMail을 변경하여도 문제가 되지 않는다. 델리게이트는 불변성이기 때문에 이론적으로는 이 기술이 잘 동작한다. 하지만 많은 개발자들이 이 코드는 컴파일러에 의해 최적화되어 지역 temp 변수가 완전히 제거될 수 있다는 사실을 알지 못했다. 만약 최적화가 수행된다면, 이 버전의 코드는 첫번째 버전의 코드와 같아지게 되며, NullReferenceException이 여전히 발생할 수 있다. 이 코드를 실제로 고치기 위해, 여러분은 다음과 같이 재작성해야 한다.
Volatile.Read 호출은 NewMail이 호출 시점에 읽혀지도록 강제하여 실제 참조가 temp 변수로 복사되도록 한다. 이제 temp는 null이 아닌 경우에만 호출될 것이다. 단계 #4: 입력을 원하는 이벤트로 전환시키는 메소드를 정의한다 컴파일러가 이벤트를 구현하는 방법 이벤트가 실제 무엇이고 어떻게 동작하는지를 살펴보자.
C# 컴파일러는 위 코드를 다음과 같이 3개의 구성체로 변환한다.
이벤트를 주시하는 타입 설계하기
C# 컴파일러는 이벤트에 대해 잘 알기 때문에, += 연산자를 다음과 같은 코드로 변환한다.
이벤트를 명시적으로 구현하기
Chapter 12 제네릭
제네릭(generic)은 코드 재사용을 제공하는 또다른 메커니즘인데, 바로 알고리즘 재사용을 제공한다. 대부분의 알고리즘들은 타입안으로 은닉화되고, CLR은 제네릭 참조타입 뿐만 아니라 제네릭 값타입의 생성도 허용하는데, 하지만 제네릭 열거타입의 생성은 허용하지 않는다. 게다가, CLR은 제네릭 인터페이스와 제네릭 델리게이트의 생성도 허용한다. 때때로 단일 메소드가 유용한 알고리즘을 은닉화할 수 있는데, 따라서 CLR은 참조타입, 값타입 혹은 인터페이스 내에 정의되는 제네릭 메소드의 생성도 허용한다. 제네릭 타입 혹은 메소드를 정의할 때, 타입(T와 같은)을 위해 명시하는 모든 변수들을 타입 파라미터(type parameter)라 부른다. 제네릭 타입 혹은 메소드를 사용할 때, 명시되는 데이터 타입은 타입 인자(type argument)라 불린다. 제네릭은 개발자에게 다음과 같은 큰 이점들을 제공한다.
the Framework Class Library의 제네릭
제네릭 내부구조 열린 타입(Open type)과 닫힌 타입(Closed type) CLR은 애플리케이션에 의해 사용되는 각각의 모든 타입들에 대해 내부 데이터 구조를 생성한다. 이들 데이터 구조를 타입 객체(type object)라 부른다. 제네릭 타입 파라미터를 가지는 타입도 또한 타입으로 간주되며, CLR은 이들 각각에 대해서도 내부 타입 객체를 생성할 것이다. 이것은 참조 타입, 값타입, 인터페이스, 델리게이트에 적용된다. 하지만, 제네릭 타입 파라미터를 가지는 타입은 열린 타입으로 불리며, CLR은 열린 타입의 인스턴스가 생성되는 것을 허용하지 않는다(인터페이스 타입의 인스턴스가 생성되는 것을 막는 것과 비슷하다). 코드가 제네릭 타입을 참조할 때, 그 코드는 제네릭 타입 인자 집합을 명시해야 한다. 만약 실제 데이터 타입이 타입 인자로 넘겨지면, 그 타입은 닫힌 타입으로 불리고, CLR은 닫힌 타입이 생성되는 것을 허용한다. 하지만 코드가 몇몇 명시되지 않은 제네틱 타입 인자를 가지는 제네릭 타입을 참조할 가능성이 있는데, 이 타입의 인스턴스는 생성될 수 없다. CLR은 타입 객체 안에 타입의 정적 필드들을 할당한다고 말했었다. 그래서 각각의 닫힌 타입들은 자신만의 정적 타입들을 가진다. 즉, List<T>가 정적 타입들을 정의한다면, 이들 필드들은 List<DateTime>과 List<String> 사이에 공유되지 않는다. 각각의 닫힌 타입들은 자신만의 정적 필드들을 가진다. 또한 제네릭 타입이 정적 생성자를 정의하면, 이 생성자는 닫힌 타입마다 한번씩 호출될 것이다.
CLR은 제약사항(constraint)라 불리는 특징을 가지는데, 이것은 어떤 타입 인자가 유효한지를 가리키도록 제네릭 타입을 정의할 수 있게 해준다. 하지만 불운하게도 제약사항은 타입 인자를 오직 열거타입으로만 제한하는 기능은 제공하지 않는데, 이 때문에 위 예제에서 정적 생성자에서 타입이 열거타입인지를 확인한다. 제네릭 타입과 상속 제네릭 타입도 하나의 타입이다. 그렇기 때문에 제네릭 타입 또한 다른 타입으로부터 파생될 수 있다. 제네릭 타입의 동일성(Identity) 때때로 제네릭 문법은 개발자들을 혼란스럽게 만든다. 그래서 몇몇 개발자들은 제네릭 타입과 모든 타입 인자들을 명시한 것에서 파생시킨 새로운 비제네릭 클래스를 정의한다.
이것이 편하게 보일지라도, 여러분의 소스코드의 가독성을 높이기 위해 명시적으로 새로운 클래스를 정의해서는 안된다. 왜냐하면 이렇게 하면 타입의 정체성과 동일성을 잃어버리기 때문이다.
이는 또한 DateTimeList를 받아들이는 메소드가 List<DateTime>를 받지 못하지만, List<DateTime>을 받아들이는 메소드는 DateTimeList도 받을 수 있는데, DateTimeList가 List<DateTime>에서 파생되었기 때문이다. 이런 현상으로 프로그래머는 아마 쉽게 혼란스러워질 것이다. C#은 타입 동등성에 전혀 영향을 끼치지 않으면서 제네릭 닫힌 타입을 간소하게 언급할 수 있는 문법을 제공한다.
여기서 using 지시자는 단순히 DateTimeList라는 심볼을 정의한다. 코드가 컴파일될 때, 컴파일러는 모든 DateTimeList를 System.Collections.Generi.List<System.DateTime>으로 대체한다. 이는 개발자가 간소화된 문법을 사용할 수 있도록 해 주는데, 그러면서도 코드의 실제 의미에는 영향을 주지 않고, 따라서 타입의 정체성과 동일성을 유지된다. 코드 폭증 제네릭 타입 파라미터를 사용하는 메소드가 JIT 컴파일될 때, CLR은 그 메소드의 IL를 가져다가 명시된 타입 인자로 치환한 후, 명시된 데이터 타입에서 동작하는 메소드에 한정적인 네이티브 코드를 생성한다. 이것이 여러분이 원하는 것이고 제네릭의 주요 특징중의 하나이다. 하지만 이것에는 단점도 있는데, CLR은 모든 메소드/타입 조합마다 네이티브 코드를 유지한다. 이것이 코드 폭증(code explosion)이다. 이는 결국 애플리케이션의 워킹 셋을 상당히 증가시키는데, 성능에 상처를 준다. 운좋게도, CLR은 코드 폭증을 줄이기 위해 몇몇 최적화을 구현했다. 먼저 어떤 메소드가 특정 타입 인자로 호출되고 나중에 그 메소드가 동일한 타입 인자로 다시 호출되면, CLR은 그 메소드/타입 조합을 위한 오직 한번만 컴파일한다. 그래서 만약 한 어셈블리가 List<DateTime>을 사용하고 완전히 다른 에셈블리(동일한 AppDomain에 로딩된)가 또한 List<DateTime>을 사용하면 CLR은 List<DateTime>에 대한 메소드를 오직 한번한 컴파일한다. CLR은 또다른 최적화를 가진다. CLR은 모든 참조타입 인자를 동일하게 간주하는데, 그 코드는 공유된다. 예를 들어, List<String>의 메소드에 대해 컴파일된 코드는 List<Stream>의 메소드를 위해서도 사용될 수 있는데, String과 Stream은 모두 참조타입이기 때문이다. 사실 모든 참조타입에 대해 동일한 코드가 사용될 것이다. 제네릭 인터페이스 제네릭 델리게이트 델리게이트와 인터페이스의 반공변성(Contra-variant)과 공변성(Covariant) 제네릭 타입 인자 델리게이트의 각 제네릭 타입 파라미터들은 covariant 혹은 contra-variant로 표시될 수 있다. 이로 인해 여러분은 제네릭 델리게이트 타입의 변수를 제네릭 파라미터 타입이 서로 다른 같은 델리게이트 타입으로 형변환 할 수 있다. 제네릭 타입 파라미터는 다음 중의 하나가 될 수 있다.
델리게이트와 마찬가지로, 제네릭 타입 파라미터를 가지는 인터페이스도 자신의 타입 파라미터를 contra-variant 혹은 covariant로 지정할 수 있다.
제네릭 메소드 제네릭 메소드와 타입 추론 제네릭과 다른 멤버 C#에서, 속성, 인덱서, 이벤트, 연산자 메소드, 생성자, 종결자 등은 그들 자신이 타입 파라미터를 가질수 없다. 하지만 그들은 제네릭 타입 내에 정의될 수 있고, 그들 멤버 안의 코드들은 타입의 타입 파라미터를 사용할 수 있다. 검증 가능성(Verifiability) 과 제약(Constraint) 제약(constraint)은 제네릭 인자로 명시될 수 있는 타입의 수를 제한하는 방법이다. 타입의 수를 제한함으로써 여러분은 이들 타입으로 좀 더 많은 것을 할 수 있다. C#의 where 토큰은 컴파일러에게 T 대신에 명시되는 모든 타입은 특정 인터페이스를 구현해야 함을 알려준다. 가상 제네릭 메소드를 재정의할 때, 재정의하는 메소드는 같은 수의 타입 파라미터를 명기해야 하고, 이들 타입 파라미터는 기반 클래스의 메소드에서 부과된 제약들을 상속해야 한다. 사실 재정의 하는 메소드는 자신의 타입 파라미터에 어떠한 제약도 명시할 수 없다. 하지만, 타입 파라미터의 이름은 변경할 수 있다. 타입 파라미터는 주 제약(primary constraint), 2차 제약(secondary constraint), 그리고/혹은 생성자 제약(constructor constraint)을 사용하여 제약될 수 있다. 주 제약(Primary Constraint) 타입 파라미터는 0개 혹은 1개의 주 제약을 명시할 수 있다. 주 제약은 봉인되지 않은 클래스를 구별하는 참조 타입이 될 수 있다. 여러분은 다음과 같은 특별한 참조 타입중의 하나를 명시할 수는 없다: System.object, System.Array, System.Delegate, System.MulticastDelegate, System.ValueType, System.Enum, or System.Void. 2개의 특별한 주 제약이 있다: class와 struct. class 제약은 명시된 타입 파라미터가 참조타입 임을 컴파일러에게 약속하는 것이다. 모든 class 타입, 인터페이스 타입, 델리게이트 타입, 혹은 배열 타입들은 모두 이 제약을 만족시킨다. struct 제약은 명시된 타입 파라미터가 값타입 임을 컴파일러에게 약속하는 것이다. 모든 값타입과 열거형이 이 제약을 만족시킨다. 하지만 컴파일러와 CLR은 모든 System.Nullable<T> 값타입을 특별하게 취급하여, nullable 타입은 이 제약을 만족시키지 못한다. Nullable<T> 타입은 자신의 타입 파라미터를 struct로 제약하기 때문에, Nullable<Nullable<T>>와 같은 회귀적 타입을 금지해야 하기 때문이다.
2차 제약(Secondary Constraint) 타입 파라미터는 0개 이상의 2차 제약을 명시할 수 있는데, 2차 제약은 인터페이스 타입을 나타낸다. 인터페이스 제약을 명시하면, 여러분은 컴파일러에게 명시된 타입 인자가 해당 인터페이스를 구현하고 있는 타입임을 약속하는 것이다. 그리고 여러분이 여러개의 인터페이스 제약을 명시할 수 있기 때문에, 타입 인자는 모든 인터페이스 제약을 구현하고 있는 타입을 명기해야 한다. 타입 파라미터 제약(때때로 naked type constraint라 언급되는)이라 불리는 또 다른 종류의 2차 제약이 있다. 이런 제약은 인터페이스 제약보다는 훨씬 적게 사용된다. 이것은 제네릭 타입 또는 메소드가 명시된 타입 인자들 사이에 어떤 관계가 있어야 함을 가리키는 것이다.
생성자 제약(Constructor Constraint) 타입 파라미터는 0개 혹은 1개의 생성자 제약을 명기할 수 있다. 생성자 제약을 명기하면, 여러분은 컴파일러에게 명기된 타입 인자는 공용이고 파라미터가 없는 생성자를 구현하고 있는 비-추상 타입 임을 약속하는 것이다. C# 컴파일러는 struct 제약을 가진 상태에서 생성자 제약을 명시하면 이를 에러로 간주하는데 이는 쓸데없이 중복되기 때문이다. 모든 값타입은 공용 파라미터 없는 생성자를 암묵적으로 제공한다.
다른 검증가능성에 관한 문제들 제네릭 타입 변수를 형변환하기 제약사항을 가지는 호환가능한 타입으로 캐스팅하지 않는 한, 제네릭 타입 변수를 다른 타입으로 캐스팅하는 것은 불법이다.
Object로 먼저 캐스팅하면 위 코드가 컴파일 가능하도록 수정할 수 있다.
만약 참조타입으로 캐스팅을 시도한다면, 여러분은 또한 C#의 as 연산자를 사용할 수 있다.
제네릭 타입 변수에 기본값을 설정하기 제네릭 타입을 참조타입으로 한정하지 않으면 제네릭 타입 변수를 null로 설정하는 것은 불법이다. 제네릭 타입 변수를 null과 비교하기 제네릭 타입 변수를 == 혹은 != 연산자를 사용하여 null과 비교하는 것은 그 제네릭 타입이 한정되었는지에 상관없이 합법이다.
하지만 T가 struct로 한정된다면, C# 컴파일러는 에러를 발생시키는데 여러분은 값타입 변수를 null과 비교하는 코드를 작성할 수 없기 때문이다. 2개의 제네릭 타입 변수를 서로 비교하기 동일한 제네릭 타입의 두 변수를 비교하는 것은 만약 그 제네릭 타입 파라미터가 참조타입으로 알려지 있지 않다면 불법이다.
두 개의 참조타입을 서로 비교하는 것은 합법인 반면, 두 개의 값타입을 서로 비교할 때 그 값타입이 == 연산자를 중복정의하지 않는다면 불법이다. 제네릭 타입 변수를 피연산자로 사용하기 제네릭 타입을 피연산자로 하여 연산자를 사용하는 것에는 많은 문제가 있다는 것을 알아야 한다. 기본타입에 적용되는 연산자들이 제네릭 타입 변수에는 적용될 수 없는데 컴파일러는 컴파일 타임에 그 타입이 무엇인지를 알지 못하기 때문이다. Chapter 13 인터페이스
CLR과 모든 관리 프로그래밍 언어들은 다중 상속을 지원하지 않는다. 어떤 종류의 다중 상속도 지원하지 않는 대신, CLR은 인터페이스를 통해 축소된 다중 상속을 지원한다. 이번 장은 인터페이스를 정의하고 사용하는 방법 뿐만 아니라 기반 클래스 보다는 인터페이스를 사용해야 할 때를 결정할 수 있는 몇몇 지침들을 제공한다. 클래스와 인터페이스 상속
인터페이스 정의하기 인테페이스는 메소드 서명들의 이름 있는 집합이다. 인터페이스는 또한 이벤트, 파라미터 없는 속성, 파라미터 있는 속성(인덱서) 들도 정의할 수 있는데, 이들 모두는 어쨌든 메소드로 연결되는 문법적 단축이기 때문이다. 하지만, 인터페이스는 모든 생성자 메소드들은 정의할 수 없다. 또한 모든 인스턴스 필드들도 허용되지 않는다. 비록 CLR이 인터페이스에 정적 메소드, 정적 필드, 상수, 정적 생성자를 정의하도록 허락하지만, C#은 인터페이스가 이들 정적 멤버들을 정의하는 것을 막는다. 인터페이스 정의는 다른 인터페이스들을 "상속"할 수 있다. 하지만, 나는 여기서 단어 상속을 좀 넓은 의미로 사용했는데, 인터페이스 상속은 클래스 상속과 정확히 동일하게 동작하지 않기 때문이다. 나는 인터페이스 상속을 다른 인터페이스 계약을 포함하는 것으로 생각하기를 좋아한다. 인터페이스를 상속하기 C# 컴파일러는 인터페이스를 구현하는 메소드가 public으로 표시되기를 요구한다. CLR은 인터페이스 메소드가 virtual로 표시되기를 요구한다. 만약 여러분이 그 메소드를 명시적으로 virtual로 표시하지 않는다면, 컴파일러가 그 메소드를 virtual과 sealed로 표시한다. 이것은 파생 클래스가 인터페이스 메소드를 재정의하는 것을 막는다. 만약 여러분이 그 메소드를 명시적으로 virtual로 표시하면, 컴파일러는 그 메소드를 virtual로(봉인되지 않은 채로) 표시한다. 이것은 파생 클래스가 그 인터페이스 메소드를 재정의 할 수 있게 해준다. 만약 인터페이스 메소드가 sealed 되면, 파생 클래스는 그 메소드를 재정의할 수 없다. 하지만, 파생 클래스는 같은 인터페이스를 재상속할 수 있으며 그 인테페이스 메소드에 대한 자신의 구현을 제공할 수 있다. 어떤 객체에 대한 인터페이스 메소드를 호출하면, 그 객체의 타입에 연관된 구현이 호출된다. 인터페이스 메소드 호출에 관해 몇가지 더 참조타입과 마찬가지로, 값타입도 0개 이상의 인터페이스를 구현할 수 있다. 하지만, 여러분은 값타입의 인스턴스를 인터페이스 타입으로 형변환할 때, 값타입 인스턴스는 박싱되어야만 한다. 이는 인터페이스 변수가 힙상에 있는 객체를 가리켜야 하는 참조여서 CLR이 그 객체의 타입 객체 포인터를 검사하여 그 객체의 정확한 타입을 결정해야 하기 때문이다. 그런 다음 박싱된 값타입의 인터페이스 메소드를 호출하면, CLR은 올바른 메소드를 호출하기 위해 그 객체의 타입 객체 포인터를 따라가서 타입 객체의 메소드 테이블을 찾는다. 암시적과 명시적 인터페이스 메소드 구현(내막에서 벌어지는 것들) 어떤 타입이 CLR에 의해 로딩될 때, 메소드 테이블이 생성되고 초기화된다. 이 메소드 테이블은 그 타입에 의해 도입된 모든 새로운 메소드마다의 엔트리 뿐만 아니라 그 타입이 상속한 모든 가상 메소드들을 위한 엔트리들도 포함한다. 상속된 가상 메소드들은 상속 계층 안의 기반 타입에 의해 정의된 메소드들 뿐만 아니라 인터페이스 타입에 의해 정의된 메소드들도 포함한다. 그러므로 만약 여러분이 다음과 같은 간단한 타입을 가지고 있다면,
이 타입의 메소드 테이블은 다음과 같은 것들을 위한 엔트리들을 포함한다.
프로그래머를 위해 간단히 하기 위해, C# 컴파일러는 SimpleType에 의해 소개된 Dispose 메소드가 IDisposable의 Dispose 메소드를 위한 구현이라고 가정한다. C# 컴파일러가 이렇게 가정하는 이유는 그 메소드가 public이고 인터페이스의 메소드와 새롭게 소개된 메소드의 서명이 동일하기 때문이다. 즉, 이들 메소드들은 동일한 파라미터와 반환타입을 가진다. 그런데, 만약 새로운 Dispose 메소드가 virtual로 표기된다고 하더라도, C# 컴파일러는 여전히 이 메소드를 인터페이스 메소드와 일치한다고 간주한다. C# 컴파일러가 이 새로운 메소드를 인터페이스 메소드와 일치시키면, SimpleType의 메소드 테이블안의 양쪽 엔트리들이 동일한 구현을 가리키도록 메타데이터를 생성시킨다. 이제 위 예제를 다음과 같이 재작성 해보자.
C#에서, 여러분이 메소드의 이름에 그 메소드를 정의한 인터페이스의 이름을 앞에 붙이면, 여러분이 명시적 인테페이스 메소드 구현(explicit interface method implementation, EIMI)을 생성한 것이다. 여러분이 명시적 인터페이스 메소드를 정의하면, 어떠한 접근자(public 혹은 private)도 붙일 수 없다. 하지만, 컴파일러가 그 메소드에 대한 메타데이터를 만들 때, 그것의 접근자를 private로 설정하여, 그 클래스의 인스턴스를 사용하는 모든 코드에서 인터페이스 메소드 호출을 막는다. 인터페이스 메소드를 호출하는 유일한 방법은 인터페이스 타입에 대한 변수를 통하는 것이다. 또한 EIMI 메소드는 virtual로 표시될 수 없으므로 재정의도 될 수 없다. 이는 EIMI 메소드가 실제로는 그 타입의 객체 모델의 일부분이 아니기 때문이다. 이것은 행동/메소드를 확실하게 표시하지 않고 한 타입에 인터페이스를 첨가하는 방법이다. 만약 이 모든 것들을 여러분이 복잡하고 뒤엉켜 있다고 생각한다면, 여어분은 제대로 이해한 것이다.
제네릭 인터페이스 이번 섹션에서는, 제네릭 인터페이스를 사용할 때 제공되는 이점들에 관해서 논의할 것이다. 먼저, 제네릭 인터페이스는 컴파일시의 타입 안정성을 제공한다. 몇몇 인터페이스들은 object를 파라미터 혹은 반환값의 타입으로 갖는 메소드를 정의한다. 코드가 이런 인터페이스 메소드를 호출할 때 모든 타입의 인스턴스에 대한 참조를 넘겨줄 수 있다. 하지만 이것은 보통 원하는 바가 아니다. 제네릭 인터페이스의 두번째 이점은 값타입과 함께 동작할 때 박싱이 훨씬 덜 발생한다는 것이다. 비-제네릭 인터페이스는 보통 파라미터로 object를 사용하기 때문에 여기에 Int32와 같은 값타입을 넘겨주면 박싱이 발생한다. 하지만 Int32을 타입 파라미터로 사용하는 제네릭 인터페이스를 사용하면, 값타입이 그대로 넘겨지게 되고 따라서 박싱이 발생하지 않는다. 제네릭 인터페이스의 세번째 이점은 한 클래스가 서로 다른 타입 파라미터를 사용하는 한 동일한 인터페이스를 여러번 구현할 수 있다는 것이다. 제네릭과 인터페이스 제약 이전 섹션에서는 제네릭 인터페이스를 사용하는 것에 대한 이점을 얘기했었는데, 이번 섹션에서는 제네릭 타입 파라미터를 인터페이스로 제약하는 것에 대한 이점을 얘기할 것이다. 첫번째 이점은 여러분은 단일 제네릭 타입 파라미터에 여러 인터페이스들로 제약할 수 있다는 것이다. 이렇게 하면, 여러분이 넘기는 파라미터의 타입은 모든 인터페이스 제약들을 구현해야만 한다.
두번째 이점은 값타입의 인스턴스를 넘길 때 박싱을 줄일 수 있다는 것이다. 이전 예제 코드에서, M 메소드에 x(Int32의 인스턴스)가 넘겨진다. x가 M에 넘겨질 때 박싱은 발생하지 않는다. 만약 M 안의 코드가 t.CompareTo(...)을 호출한다면, 그 호출을 할때에도 여전히 박싱은 발생하지 않는다(CompareTo에 넘겨지는 인자에 대해서는 박싱이 발생할 것이다). 반면에, 만약 M이 다음과 같이 선언되어 있다면,
M에 x를 넘기기 위해서 x는 박싱되어야 할 것이다. 인터페이스 제약에 대해, C# 컴파일러는 값타입에 대한 인터페이스 메소드 호출이 박싱이 없이 호출되도록 하는 IL 명령들을 발생시킨다. 인터페이스 제약을 사용하는 방법 외에는 C# 컴파일러가 이런 IL 명령들을 발생시키게 하는 다른 방법은 없다. 그러므로 값타입에 대한 인터페이스 메소드 호출은 항상 박싱을 유발시킨다. 같은 메소드 이름과 서명을 가지는 여러 인터페이스들을 구현하기 명시적 인터페이스 메소드 구현(EIMI)으로 컴파일시 타입 안정성 개선하기
위 코드에는 이상적이지 않는 2개의 특이점이 존재한다
이 문제점들은 EIMI를 사용하여 고쳐질 수 있다.
하지만 여기서도 우리가 인터페이스 타입에 대한 변수를 정의한다면, 다시 컴파일 타임 타입 안정성을 잃고 원치 않는 박싱을 경험할 수 있다.
명시적 인터페이스 메소드 구현(EIMI)를 조심하라 EIMI를 사용할 때 존재하는 몇가지 결점들을 이해하는 것은 중요하다. 그리고 이러한 결점들 때문에 여러분은 가급적 EIMI를 피하려고 노력해야 한다. 제네릭 인터페이스는 EIMI 사용을 꽤 많이 피할 수 있도록 해주지만, 그래도 여전히 EIMI를 사용해야 할 때가 있다(같은 메소드 이름과 서명을 가지는 2개의 인터페이스를 구현해야 할 때). EIMI에는 다음과 같은 문제점들이 있다.
디자인: 기반 클래스 아니면 인터페이스?
PART 3 필수 타입 Chapter 14 문자, 문자열 그리고 텍스트와 작업하기 이번 장에서, 나는 Microsoft .NET 프레임워크에 있는 개별 문자와 문자열과 함께 작업하는 메커니즘을 설명할 것이다. 문자 .NET Framework에서 문자는 항상 16비트 유니코드 값으로 표현된다. 문자는 System.Char 구조체의 인스턴스로 표현된다. 다양한 숫자 타입들을 Char 인스턴스로 변환하거나 그 반대로 변환하는 방법에는 3가지가 있다.
System.String 타입 String은 변하지 않는 연속된 문자들을 나타낸다. String 타입은 Object에서 바로 파생되었기 때문에 참조 타입이고, 그래서 String 객체들은 항상 힙에 존재하고 결코 스레드 스택상에 존재하지 않는다. String 타입은 또한 몇몇 인터페이스들(IComarable/IComparable<String>, IClonable, IConvertible, IEnumerable/IEnumerable<Char>, IEquatable<String>)을 구현한다. String 생성하기 C#에서 리터럴 문자열로부터 String 객체를 구성하기 위해 여러분은 new 연산자를 사용할 수 없다. 대신에 여러분은 간소화된 문법을 사용해야만 한다.
newobj IL 명령은 어떤 객체의 새로운 인스턴스를 생성한다. 하지만 위 코드에 대한 IL 코드에는 어떠한 newobj 명령도 존재하지 않는다. 대신에 여러분은 특별한 idstr IL 명령을 볼 수 있는데, 이 명령은 메타데이터로부터 얻은 리터럴 문자열을 사용하여 String 객체를 생성한다. 이는 CLR이 사실 리터럴 String 객체를 생성하는 특별한 방법을 가지고 있음을 보여주는 것이다. C#은 인용부호 사이의 모든 문자들을 문자열의 일부로 간주하는 문자열을 선언하는 특별한 방법을 제공한다. 이런 특별한 선언은 verbatim string이라 불리며 verbatim string character(@)을 사용한다.
String은 불변이다 불변 문자열은 몇몇 이점들을 제공한다. 먼저 이것은 실제 문자열을 변경하지 않고 그 문자열에서 연산을 수행할 수 있게 해준다. 불변 문자열은 또한 문자열을 조작하거나 접근할 때 스레드 동기화 문제가 없음을 의미한다. 게다가 CLR이 단일 String 객체를 통해 동일한 String 내용을 여러번 공유하는 것이 가능하다. String 비교하기 프로그래밍적 문자열을 비교할 때, 여러분은 항상 StringComparision.Ordinal 혹은 StringComparison.OrdinalIgnoreCase를 사용해야 한다. 이것은 어떠한 언어적 방식에도 영향을 받지 않고 비교를 수행하는 가장 빠른 방식인데, 왜냐하면 비교를 수행할 때 문화적 정보가 고려되지 않기 때문이다. String Interning 만약 여러분의 애플리케이션이 문자열을 자주 비교하거나, 혹은 많은 String 객체들이 같은 값을 가질 수 있을 것 같다면, CLR의 String interning 메커니즘을 사용하여 여러분은 본질적으로 애플리케이션의 성능을 향상시킬 수 있다. CLR은 자신이 초기화될 때 키가 문자열이고 값은 관리힙에 있는 String 객체에 대한 참조인 내부 해시 테이블을 생성한다. 그 테이블은 처음엔 당연히 비어 있다. String 클래스는 여러분이 이 내부 해시 테이블에 접근할 수 있도록 해주는 2개의 메소드를 제공한다.
String Pooling String의 문자들과 text element들을 조사하기 다른 String 연산들 String을 효율적으로 생성하기 StringBuilder 객체 생성하기 StringBuilder 멤버들 한 객체의 String 표현을 얻기: ToString Specific Formats and Cultures Formatting Multiple Objects into a Single String Providing Your Own Custom Formatter 객체를 얻기 위해 String을 파싱하기: Parse 문자열을 파싱할 수 있는 모든 타입은 Parse라 불리는 공용 정적 메소드를 제공한다. 이 메소드는 String을 취하고 해당 타입의 인스턴스를 반환하는데, 그런 면에서 Parse는 팩토리처럼 동작한다. FCL에서, Parse 메소드는 모든 숫자 타입 뿐만 아니라 DateTime, TimeSpan 그리고 몇몇 다른 타입들에서도 존재한다. 인코딩: 문자와 바이트 사이를 변환시키기 CLR에서는, 모든 문자들은 16비트 유니코드 값으로 표현되고 모든 문자열은 16비트 유니코드 값들로 구성된다. FCL은 문자를 쉽게 인코딩하고 디코딩하게 해주는 몇몇 타입들을 제공한다. 가장 자주 사용되는 2개의 인코딩은 UTF-16과 UTF-8이다.
FCL은 다음과 같은 자주 사용되지 않는 인코딩들도 지원한다.
Encoding and Decoding Streams of Characters and Bytes Base-64 String Encoding and Decoding 보안 String 여러분이 System.Security.SecureString 객체를 생성하면, 이것은 내부적으로 문자 배열을 포함하는 관리되지 않는 메모리 블록을 할당한다. 관리되지 않는 메모리가 사용되면 가비지 컬렉터는 이를 알지 못한다. 이들 문자열의 문자들은 암호화되는데, 민감한 정보들을 악성 비안전/비관리되는 코드로부터 보호해준다. 여러분은 보안 문자열에 문자를 추가, 삽입, 제거 혹은 설정할 수 있다. 이런 메소드들이 호출될 때마다, 내부적으로 그 메소드는 문자들을 복호화하여 필요한 연산을 바로 수행한 후에 다시 암호화한다. 즉 문자들은 아주 짧은 시간 동안 복호화된 상태로 있게 된다.
Chapter 15 열거 타입과 비트 플래그 이번 장에서, 나는 열거 타입과 비트 플래그를 얘기할 것이다. 윈도우와 많은 프로그래밍 언어가 오랫동안 이 구성체들을 사용해왔기 때문에, 여러분들 대다수는 이미 이것들을 사용하는 방법에 익숙할 것이다. 하지만, CLR과 FCL은 이 열거 타입과 비트 플래그가 실제 객체 지향적 타입이 되도록 함께 작업하여 아마도 대부분의 개발자들이 친숙하지 않은 멋진 특징들을 제공한다. 열거 타입 열거타입(enumerated type)은 심볼이름과 값 쌍의 집합을 정의하는 타입이다. 모든 열거 타입은 System.Enum에서 파생되고, System.Enum은 System.ValueType에서 파생되고, System.ValueType은 System.Object에서 파생된다. 그러므로 열거타입은 값타입이고 언박상과 박싱 형태로 표현될 수 있다. 하지만 다른 값타입과는 달리, 열거타입은 메소드, 속성, 이벤트 등을 정의할 수 없다. 하지만 여러분은 C#의 확장 메소드를 사용하여 열거타입에 메소드를 추가하는 것을 흉내낼 수 있다. C# 컴파일러는 열거타입을 기본 타입으로 취급한다. 그렇기 때문에, 여러분은 열거타입 인스턴스들을 조작하기 위해 많은 친숙한 연산자들(==, !=, <, >, <=, >=, +, -, ^, &, |, ~, ++, --)을 사용할 수 있다. 게다가 C# 컴파일러는 여러분이 한 열거타입의 인스턴스를 다른 열거타입으로 명시적으로 캐스팅할 수 있게 해준다. 여러분은 또한 열거타입 인스턴스를 숫자타입으로 명시적 캐스팅을 할 수 있다. 열거타입 내의 각 심볼 이름 별로 하나의 요소를 포함하는 배열을 얻을 수 있는 메소드들이 있다: System.Enum.GetValues와 System.Type.GetEnumValues.
또한 열거타입의 심볼을 반환하는 메소드들도 있다: System.Enum.GetName(), System.Type.GetNumName(). 비트 플래그 열거타입에 메소드 추가하기 Chapter 16 배열 배열은 여러분이 여러 항목들을 하나의 콜렉션으로 처리할 수 있도록 해주는 메커니즘이다. Microsoft .NET CLR은 일차원 배열, 다차원 배열, 그리고 jagged array(즉, 배열의 배열)을 지원한다. 모든 배열 타입은 System.Object로부터 파생된 System.Array 추상 클래스로부터 암시적으로 파생된다. 이는 배열이 항상 관리힙에 할당되는 참조타입이라는 것이다. 지금까지, 나는 일차원 배열을 생성하는 방법을 설명했다. 가능하다면, 여러분은 일차원의 0기반 배열을 고수할 필요가 있다. 이는 때때로 SZ 배열(SZ array) 혹은 벡터로 불린다. 벡터는 가장 좋은 성능을 보이는데, 여러분이 배열을 다루는 특화된 IL 명령을 사용할 수 있기 때문이다. 배열 요소를 초기화하기 이전 섹션에서, 나는 배열 객체를 생성하는 방법을 보여주었고, 그런 다음 그 배열의 요소들을 초기화하는 방법을 보여주었다. C#은 여러분이 이 두 동작을 한 문장으로 할 수 있는 문법을 제공한다.
중괄호 내에 포함된 콤마로 구분된 토큰 집합을 배열 초기화자(array initializer)라고 부른다. 각 토큰은 임의적으로 복잡한 표현, 혹은 다차원 배열의 경우엔 중첩된 배열 초기화자가 될 수 있다.
배열을 형변환하기 참조타입 요소를 가지는 배열에 대해, CLR은 여러분이 원본 배열의 요소 타입을 목적 타입으로 암시적으로 형변환하는 것을 허용한다. 형변환이 성공하려면, 양쪽 배열 타입은 같은 차원수를 가져야 하고 원본 요소 타입에서 목적 요소 타입으로의 암시적 혹은 명시적 변환이 존재해야 한다. CLR은 값타입 요소를 가지는 배열을 다른 타입으로 형변환하는 것을 허용하지 않는다. (하지만 Array.Copy 메소드를 사용하여, 원하는 결과를 얻기 위해 여러분은 새로운 배열을 생성하고 그것의 요소들을 덧붙일 수 있다).
Copy 메소드는 변환이 필요하다면 요소들을 복사하면서 각 배열 요소들을 변환시킨다. Copy 메소드는 다음과 같은 변환들을 수행할 수 있다.
어떤 경우엔, 한 타입을 다른 타입으로 배열을 형변환하는 것이 유용하다. 이런 종류의 기능을 배열 공변성(array covariance)이라 부른다. 배열 공변성을 사용할 때, 여러분은 이와 연관된 성능 하락을 알아야 한다. 다음 코드를 보자.
만약 여러분이 단지 어떤 배열 요소들을 다른 배열로 복사해야 한다면, System.Buffer의 BlockCopy 메소드가 Array의 Copy 메소드보다 더 빨리 수행한다. 하지만, Buffer의 BlockCopy는 오직 기본타입만 지원한다. 이 메소드는 Array의 Copy 메소드와 같은 형변환 기능을 제공하지 않는다. 만약 여러분이 한 배열에서 다른 배열로 배열 요소 집합을 신뢰적으로 복사하길 원한다면, System.Array의 ConstrainedCopy 메소드를 사용할 수 있다. 이 메소드는 복사 연산이 완료되거나 아니면 목적 배열 내에서 어떠한 데이터도 파괴되지 않고 예외를 던질 것이다. 이는 ConstrainedCopy가 constrained execution region(CER)에서 사용되는 것을 허용한다. 이런 보장을 제공하기 위해, ConstrainedCopy는 원본 배열의 요소타입이 목적 배열의 요소 타입과 같거나 파생되어야 함을 요구한다. 게다가, 이것은 어떠한 박싱, 언박싱, 다운캐스팅을 수행하지 않을 것이다. 모든 배열은 System.Array로부터 암묵적으로 파생된다 여러분이 다음과 같이 배열 변수를 선언하면,
CLR은 AppDomain에 FileStream[] 타입을 자동으로 생성한다. 이 타입은 System.Array 타입에서 파생될 것이고, 따라서 System.Array에 정의된 모든 인스턴스 메소드들과 속성들이 상속된다. 모든 배열은 IEnumerable, ICollection, 그리고 IList을 암묵적으로 구현한다 System.Array는 이들 비-제네릭 인터페이스들을 구현하는데, 이들은 모든 요소들을 System.Object로 취급하기 때문이다. 하지만 System.Array가 이 인터페이스의 제네릭 버전을 구현하면 더 좋을 것인데, 제네릭 버전이 더 좋은 성능 뿐만 아니라 더 좋은 컴파일시의 타입 안정성을 제공하기 때문이다. CLR 팀은 System.Array가 IEnumerable<T>, ICollection<T>, IList<T>를 구현하길 원치 않았는데, 다차원 배열과 비제로 기반 배열 때문이었다. 대신에 CLR 팀은 약간의 속임수를 썼다. 일차원이고 제로기반 배열 타입이 생성되면, CLR은 IEnumerable<T>, ICollection<T>, IList<T>를 구현한 배열 타입을 자동으로 생성하고, 배열 타입의 기반 타입이 참조타입인 한 그 기반 타입에 대한 3개의 인터페이스들을 또한 구현한다. 다음 계층도 다이어그램은 이점을 명백하게 보여준다.
그래서 예를 들어 다음과 같은 코드가 있어서
CLR이 FileStream[] 타입을 생성하면, 이 타입은 자동으로 IEnumerable<FileStream>, ICollection<FileStream>, IList<FileStream> 인터페이스를 구현한다. 게다가 이 타입은 또한 기반 타입를 위한 인터페이스들도 구현한다: IEnumerable<Stream>, IEnumerable<Object>, ICollection<Stream>, ICollection<Object>, IList<Stream>, IList<Object>. 이들 모든 인터페이스들이 CLR에 의해 자동으로 구현되기 때문에, fsArray 변수는 이들 인터페이스가 존재하는 어느 곳이든지 사용될 수 있는 것이다. 만약 배열이 값타입 요소들을 포함한다면, 그 배열 타입은 그 요소의 기반 타입에 대한 인터페이스들은 구현하지 않는다. 그 이유는 값타입의 배열은 참조타입의 배열과는 다른 메모리상의 구조를 가지기 때문이다. 배열을 넘기고 반환하기 만약 여러분이 배열에 대한 참조를 반환하는 메소드를 정의한다면, 그리고 그 배열이 어떠한 요소도 가지지 않는다면, 여러분의 메소드는 null 이나 아니면 0개의 요소를 가지는 배열에 대한 참조를 반환할 수 있다. Microsoft는 0길이 배열을 반환하기를 강력 권장하는데, 그렇게 하는 것이 개발자가 해당 메소드 호출하는 코드를 더 간단하게 작성할 수 있기 때문이다. 비제로 기반 배열을 생성하기 배열 내부 내부적으로, CLR은 사실 2종류의 배열을 지원한다.
안전하지 않은 배열 접근과 고정크기 배열 Chapter 17 델리게이트 이번 장에서는 콜백 함수에 대해서 얘기한다. 콜백 함수는 수십년 동안 사용된 매우 유용한 프로그래밍 메커니즘이다. Microsoft .NET Framework은 델리게이트(delegate)를 사용함으로써 콜백 함수 메커니즘을 드러낸다. 델리케이트의 첫인상 비관리 C/C++에서 비멤버 함수의 주소는 단순한 메모리 주소이다. 이 주소는 파라미터의 수, 파라미터의 타입, 함수의 반환타입등과 같은 어떠한 추가적인 정보를 수반하지 않는다. 즉 비관리 C/C++ 콜백함수는 타입에 안전하지 않다. .NET Framework에서 콜백함수는 비관리 윈도우 프로그래밍만큼 유용하고 널리 퍼져 있다. 하지만 .NET Framework는 델리게이트라 불리는 타입에 안전한 메커니즘을 제공한다. 델리게이트를 사용하여 정적 메소드를 콜백하기 델리게이트 객체가 충분한 보안/접근성을 가지는 코드에 의해 생성되는 한, 어떤 타입이 그 델리게이트를 통해 다른 타입의 사적 멤버를 호출하는 코드를 가지는 것은 보안/접근성 위반이 아니다. C#과 CLR 모두 메소드를 델리게이트로 연결할 때 참조타입의 covariance와 contra-variance를 허용한다. covariance는 메소드가 델리게이트의 반환타입에서 파생된 타입을 반환할 수 있음을 의미하고, contra-variance는 메소드가 델리게이트의 파라미터 타입의 기반 타입을 파라미터로 취할 수 있음을 의미한다. 예를 들어, 델리게이트가 다음과 같이 정의되어 있다면,
델리게이트 타입에 연결할 메소드의 인스턴스로서 다음과 같은 메소드가 가능하다.
델리게이트를 사용하여 인스턴스 메소드를 콜백하기 델리게이트의 비밀을 파헤치기 아래 코드를 살펴보자.
컴파일러가 위와 같은 코드를 보면, 컴파일러는 실제 다음과 같은 완벽한 클래스를 정의한다.
컴파일러에 의해 정의된 클래스는 4개의 메소드들을 가진다: 생성자, Invoke, BeginInvoke, EndInvoke. 이번 장에서는 생성자와 Invoke 메소드에 중점을 둘 것이다. BeginInvoke와 EndInvoke 메소드는 .NET Framework의 Asynchronous Programming Model(APM)과 관련이 있는데, 이것은 이제 구식으로 간주되고 태스크로 대체되었다. 모든 델리게이트 타입은 MulticastDelegate로부터 파생되기 때문에, 이들은 MulticastDelegate의 필드, 속성 그리고 메소드들을 상속받는다. 이들 멤버들 중에서, 3개의 비공용 필드들이 아마도 가장 중요할 것이다.
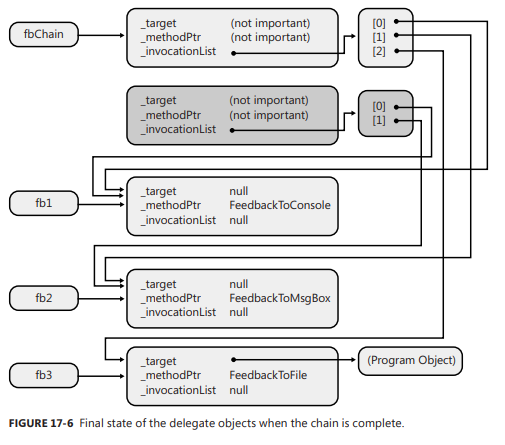
모든 델리게이트는 2개의 파라미터(객체에 대한 참조와 콜백 메소드를 언급하는 정수)를 취하는 생성자를 가진다. 하지만 나는 Program.FeedbackToConsole 혹은 p.FeedbackToFile와 같이 값을 사용했다. 이것만 보면 이 코드는 컴파일되지 않아야 한다. 하지만, C# 컴파일러는 델리게이트가 생성중 임을 알고 어떤 객체와 메소드가 언급되어야 하는지를 결정하기 위해 소스코드를 분석한다. 그래서 그 객체에 대한 참조가 생성자의 object 파라미터로 넘겨지고, 해당 메소드를 구별하는 특별한 IntPtr 값이 method 파라미터를 위해 넘겨진다. 정적 메소드에 대해서는 object 파라미터가 null이 된다. 델리게이터를 사용하여 많은 메소드들을 콜백하기(Chaining) 델리게이트 자체로도 믿을수 없이 유용하다. 하지만 여기에 체이닝을 추가하면서, 델리게이트는 더 유용하게 되었다. 체이닝(Chaining)은 델리게이트 객체들의 집합으로서, 집합안의 델리게이트들에 의해 표현되는 모든 메소드들을 호출할 수 있는 능력을 제공한다.
델리게이트 체인을 위한 C#의 지원 C# 개발자를 위해, C# 컴파일러는 델리게이트 타입의 인스턴스를 위해 +=와 -=의 연산자 오버로드를 자동으로 제공한다. 이들 연산자는 각각 Delegate.Combine과 Delegate.Remove를 호출한다. 델리게이트 체인 소환에 대한 더 많은 제어를 가지기 체인 안의 각 델리게이트들을 호출하는 것은 확실히 매우 간단한 알고리즘이다. 비록 이 간단한 알고리즘은 대부분의 상황에서 만족스럽지만, 이것은 또한 많은 제한들을 가진다. 예를 들어, 콜백 함수들의 반환값들은 마지막 것만 제외하고는 모두 버려진다. 또 다른 문제점으로, 체인 안의 델리게이트들이 직렬로 호출되기 때문에, 그들중의 하나에 문제가 발생하면 이어지는 모든 델리게이트들은 중지된다. 이런 알고리즘으로는 대처가 안되는 상황들을 위해, MulticastDelegate 클래스는 GetInvocationList라는 인스턴스 메소드를 제공하는데, 이것으로 여러분은 체인 안의 각 델리게이트를 명시적으로 호출할 수 있다. 델리게이트 정의는 이미 충분하다(제네릭 델리게이트)
현재 .NET Framework는 17개의 Action 델리게이트를 준비했다. Action 델리게이트 뿐만 아니라, .NET Framework는 17개의 Func 델리게이트도 준비했는데, 이것은 반환값을 가지는 콜백 메소드를 허용한다.
델리게이트를 위한 C#의 문법적 편의 기능 문법적 단축 #1: 델리게이트 객체를 생성할 필요가 없다
문법적 단축 #2: 콜백 메소드를 정의할 필요가 없다(람다 표현식)
문법적 단축 #3: 클래스 내 지역 변수를 콜백 메소드에 넘기기 위해 포장할 필요가 없다 델리게이트와 리플렉션 Chapter 18 커스텀 어트리뷰트 커스텀 어트리뷰트(custom attribute)는 여러분이 여러분의 코드 구성체를 선언적으로 표기할 수 있게 해주어 특별한 기능들을 사용 가능하게 해준다. 커스텀 어트리뷰트는 정보가 거의 모든 메타데이터 테이블 항목에 정의되고 적용될 수 있게 해준다. 이런 확장 가능한 메타데이터 정보는 런타임시에 질의되어 코드가 수행되는 방식을 동적으로 변경할 수 있게 해준다. 커스텀 어트리뷰트를 사용하기 커스텀 어트리뷰트에 대해 여러분이 알아야 할 첫번째 사항은 커스텀 어트리뷰트가 추가 정보를 타켓에 단순히 연결시키는 방법이라는 것이다. 컴파일러는 추가 정보를 만들어서 관리 모듈의 메타데이터에 넣는다. 대부분의 어트리뷰트는 컴파일러에게는 아무런 의미가 없다. 컴파일러는 단순히 소스코드의 어트리뷰트를 감지하여 해당하는 메타데이터를 만들 뿐이다. CLR은 어트리뷰트가 파일의 메타데이터 안에 표현될 수 있는 모든 것에 적용될 수 있게 해준다: TypeDef(클래스, 구조체, 열거형, 인터페이스, 델리게이트), MethodDef(생성자 포함), ParamDef, FieldDef, PropertyDef, EventDef, AssemblyDef, ModulDef. 특히, C#은 여러분이 다음과 같은 타켓을 정의하는 소스코드에만 어트리뷰트를 적용할 수 있게 해준다: 어셈블리, 모듈, 타입(클래스, 구조체, 열거형, 인터페이스, 델리게이트), 필드, 메소드(생성자 포함), 메소드 파라미터, 메소드 반환값, 속성, 이벤트, 제네릭 타입 파라미터. 여러분이 어트리뷰트를 적용할 때, 어트리뷰트가 적용되는 타겟을 알리는 접두사를 명기할 수 있다. 대부분의 경우 여러분은 접두사를 생략할 수 있으며, 그러면 컴파일러가 해당 타켓을 결정할 수 있다. 몇몇 경우엔 접두사가 반드시 필요하며, 아래 예제에서는 이탤릭체로 표시했다.
커스텀 어트리뷰트는 단순히 어떤 타입의 인스턴스이다. Command Language Specification(CLS) 준수를 위해, 커스텀 어트리뷰트는 공용 추상 System.Attribute로부터 직접적으로 혹은 간접적으로 파생되어야 한다. C#은 오직 CLS를 준수하는 어트리뷰트만 허용한다. 여러분 자신의 어트리뷰트 클래스를 정의하기 여러분은 어트리뷰트를 논리적 상태 용기로 생각할 수 있다. 즉, 어떤 어트리뷰트 타입이 클래스인 한, 그 클래스는 간단해야 한다. 그 클래스는 단지 하나의 공용 생성자를 제공해야 하고 그 생성자는 어트리뷰트의 의무적(위치) 상태 정보를 받아들인다. 그리고 그 클래스는 공용 필드/속성을 제공할 수 있는데, 그 멤버는 어트리뷰트의 선택적(이름있는) 상태 정보를 받아들인다. 그 클래스는 어떠한 공용 메소드, 이벤트 혹은 다른 멤버들을 제공해서는 안된다. 여러분이 정의한 어트리뷰트가 합법적으로 어디에 적용되어야 하는지를 컴파일러에게 알려주려면, 여러분은 System.AttributeUsageAttribute 클래스의 인스턴스를 여러분의 어트리뷰트 클래스에 적용해야 한다. 어트리뷰트 생성자와 필드/속성 데이터 타입 어트리뷰트 클래스의 인스턴스 생성자, 필드 그리고 속성들을 정의할 때, 여러분은 데이터 타입의 작은 하위 집합으로 멤버의 타입을 한정해야 한다. 특히나 합법적 데이터 타입 집합은 다음으로 제약된다: Boolean, Char, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, Single, Double, String, Type, Object, 혹은 열거 타입. 또한 여러분은 이런 타입들의 일차원의 제로기반 배열도 사용할 수 있지만, 생성자가 배열을 취하는 것은 CLS에 부합하지 않기 때문에 이를 피해야 한다. 논리적으로, 컴파일러가 타켓에 적용되는 커스텀 어트리뷰트를 발견하면, 컴파일러는 그 어트리뷰트의 생성자를 호출하여 어트리뷰트 인스턴스를 생성하고, 명시된 파라미터들을 그 생성자에 넘긴다. 그런 후에, 컴파일러는 향상된 생성자 문법을 통해 명시된 값들을 사용하여 모든 공용 필드와 속성들을 초기화한다. 이제 커스텀 어트리뷰트 객체가 초기화 되었으므로, 컴파일러는 그 어트리뷰트 객체의 상태를 직렬화하여 타겟의 메타데이터 테이블 항목에 넣는다.
커스텀 어트리뷰트의 사용을 검출하기 여러분이 여러분 자신의 어트리뷰트 클래스를 정의한다면, 여러분은 또한 (어떤 타겟에서) 여러분의 어트리뷰트 클래스의 인스턴스의 존재여부를 확인하는 코드를 구현해서 다른 코드 경로를 수행하게 해야 한다. 이것이 커스텀 어트리뷰트가 매우 유용하게 만드는 것이다. FCL은 어트리뷰트의 존재여부를 확인할 수 있는 많은 방법들을 제공한다. 만약 여러분이 System.Type 객체를 사용한다면, IsDefined 메소드를 사용할 수 있다. 하지만 때때로 여러분은 타입 보다는 어셈블리, 모듈 혹은 메소드와 같은 타겟에 대한 어트리뷰트를 확인하길 원할 수도 있다. System.Reflection.CustomAttributeExtensions 클래스는 타겟에 연관된 어트리뷰트들을 얻을 수 있는 3개의 정적 메소드들을 정의한다.
타겟에 어트리뷰트가 적용되었는지만을 보기 원한다면, 여러분은 IsDefined를 호출해야 하는데 이것이 다른 두개의 메소드보다 더 효율적이기 때문이다. 하지만 여러분은 어트리뷰트가 타겟에 적용될 때 그 어트리뷰트의 생성자에 파라미터를 명시할 수 있고 선택적으로 필드와 속성을 설정할 수 있음을 안다. IsDefined를 사용하는 것은 어트리뷰트 객체를 생성하고 그 생성자를 호출하거나 혹은 필드와 속성을 설정하지 않는다. 만약 어트리뷰트 객체를 생성하기 원한다면, 여러분은 GetCustomAttributes나 GetCustomAttribute를 호출해야 한다. 이들중 하나를 호출할 때마다, 이것은 명시된 어트리뷰트 타입의 새로운 인스턴스를 생성하고 그 인스턴스의 필드와 속성 각각을 소스코드 안에 명시된 값에 근거하여 설정한다. 이들 메소드들은 적용된 어트리뷰트 클래스의 완전히 생성된 인스턴스에 대한 참조를 반환한다. 여러분이 IsDefined, GetCustomAttribute, GetCustomAttributes에 클래스를 넘길 때, 이들 메소드들은 여러분이 명시한 어트리뷰트 클래스 혹은 그 클래스로부터 파생된 모든 어트리뷰트 클래스의 적용을 찾는다. 만약 여러분의 코드가 특정 어트리뷰트 클래스를 찾고 있는 거라면, 반환값에 추가적인 확인을 하여 이 메소드가 반환한 것이 여러분이 찾고 있는 바로 그것인지를 보장해야 한다. 또한 여러분의 어트리뷰트 클래스를 sealed로 정의하여 잠재적인 혼란과 추가적인 확인을 제거할 수도 있다. 두 어트리뷰트 인스턴스를 서로에 대해 매칭시키기 지금 여러분의 코드는 어트리뷰트의 인스턴스가 타겟에 적용되었는지의 여부를 확인하는 방법을 알게 되었으므로, 그들이 어떤 값을 가지고 있는지를 보기 위해 해당 어트리뷰트의 필드들을 확인하고 싶을 수도 있다. System.Attribute는 Object의 Equals 메소드를 재정의하는데, 내부적으로 이 메소드는 리플렉션을 사용한다. 여러분은 Equals 메소드를 재정의하여 성능을 향상시킬 수 있다. System.Attribute은 또한 가상 Match 메소드를 제공하는데, 여러분은 더 많은 의미를 제공하기 위해 이를 재정의할 수 있다. Match의 기본 구현은 Equals를 호출하고 그 결과를 반환하는 것이다.
어트리뷰트 파생 객체 생성없이 커스텀 어트리뷰트의 사용을 검출하기 Conditional 어트리뷰트 클래스 System.Diagnostics.ConditionalAttribute를 가지는 어트리뷰트 클래스는 conditional 어트리뷰트 클래스라 불린다.
컴파일러가 타겟에 적용되어 있는 CondAttribute의 인스턴스를 볼 때, 컴파일러는 그 타겟이 포함되어 있는 코드가 컴파일될 때 TEST혹은 VERIFY 심볼이 정의되어 있을 때만 그 어트리뷰트 정보를 메타데이터에 넣을 것이다. 하지만, 그 어트리뷰트 클래스 정의 메타데이터와 구현은 여전히 어셈블리 내에 존재한다. Chapter 19 Nullable 값타입 여러분도 알다시피, 값타입의 변수는 결코 null이 될 수 없다. 그것은 항상 값을 가지고 있다. 하지만 이것이 문제가 되는 경우가 있다. 이것을 개선하기 위해, Microsoft는 CLR에 널이 허용되는 값타입이라는 개념을 추가했다. FCL에는 System.Nullable<T> 구조체가 정의되어 있다. 이 구조체는 null이 될 수도 있는 값타입의 개념을 구현한다. Nullable<T> 자체가 값타입이기 때문에, 이것의 인스턴스는 비교적 경량급이다. 즉, 인스턴스는 여전히 스택상에 존재할 수 있고, 인스턴스의 크기는 원래 값타입의 크기에 Boolean 필드 크기만큼 추가된다.
Nullable 값타입을 위한 C#의 지원 C#은 nullable 값타입과 함께 동작하기 위한 깔끔한 문법을 제공한다.
C#에서 Int32? 은 Nullable<Int32>와 동일한 표기이다. C#은 또한 nullable 인스턴스에 대해 변환과 캐스트를 수행한다. 그리고 연산자를 지원한다.
여러분은 nullable 인스턴스를 다루는 것이 상당량의 코드를 발생시킨다는 사실을 알아야 한다. C#의 Null-Coalescing 연산자 C#은 null-coalescing 연산자(??)를 가지는데, 이 연산자는 2개의 피연산자를 취한다. 만약 왼쪽 피연산자가 null이 아니면, 그 피연산자의 값이 반환된다. 만약 왼쪽 피연산자가 null이면, 오른쪽 피연산자의 값이 반환된다.
CLR은 nullable 값타입을 위해 특별한 지원을 한다 nullable 값타입을 박싱하기 CLR이 Nullable<T> 인스턴스를 박싱할 때, CLR은 그 인스턴스가 null인지를 확인한다. 만약 그렇다면, CLR은 실제 어떠한 것도 박싱하지 않고 null을 반환한다. 만약 nullable 인스턴스가 null이 아니면, CLR은 nullable 인스턴스에서 값을 꺼내서 그 값을 박싱한다.
nullable 값타입을 언박싱하기 CLR은 박싱된 값타입을 T 혹은 Nullable<T>로 언박싱되게 할 수 있다. 만약 박싱된 값타입에 대한 참조가 null이고, 여러분은 그것을 Nullable<T>로 언박싱한다면, CLR은 Nullable<T>의 값을 null로 설정한다. nullable 값타입을 통해 GetType을 호출하기 Nullable<T> 객체에서 GetType을 호출하면, CLR은 실제로 거짓말을 하는데, Nullable<T> 타입 대신에 T 타입을 반환한다. nullable 값타입을 통해 인터페이스 메소드를 호출하기 다음 코드에서 저자는 Nullable<Int32> 타입을 IComprable<int32> 인터페이스 타입으로 캐스팅한다. 하지만 Nullable<T> 타입은 Int32가 구현하듯이 IComparable<int32> 인터페이스를 구현하지 않는다. C# 컴파일러는 이 코드를 어쨋든 컴파일하는데, CLR의 검증기는 이 코드를 검증된 것으로 간주하여 여러분이 좀 더 편리한 문법을 사용할 수 있도록 해준다.
|

출처1
https://m.blog.naver.com/PostView.nhn?blogId=oidoman&logNo=90160134036&proxyReferer=https:%2F%2Fwww.google.com%2F
출처2